Искусственный интеллект для бизнеса - практика применений
То, что искусственный интеллект уже реально существует и даже создается в Украине, уже не секрет. Об этом нам рассказал в интервью Олесь Петрив. И, может, нам с нашими темпами внедрения даже обычного электронного документооборота кажется не время смотреть на такие инновации. Но технологии движутся, и смартфоны сегодня в кармане каждого, а с ними нам доступны все прелести компьютерного мира. И мы сами становимся все более доступной аудиторией для бизнесов, которые делают ставку на машинный интеллект. Наблюдать, потреблять или присматриваться и имплементировать в свою работу?
Наш гость Борис Працюк расскажет о практическом опыте продажи и использования AI технологий:
- как уже сейчас выстраивается бизнес вокруг AI, почему американские компании развивают свои стартапы в Украине;
- какая работа искусственного интеллекта востребована, от подсчета апельсинов, дизайна мебели и распознавания положений тела работников до инвестиционных проектов и автопилотирования;
- где есть бесплатные библиотеки для обучения нейросети, и почему нужно лицензирование;
- сколько стоит проект, специалист по AI, аренда сервера;
- тема e-commerce и магазины будущего: во что вкладывают миллиарды Amazon, eBay и Alibaba;
- где не стоит доверяться неживому существу;
- и когда и для чего люди сами захотят стать киборгами, как это будет происходить, что будет с несогласными.
И еще много интересного в нашем видео расскажет Борис Працюк, CTO в американском стартапе Scalarr, в прошлом Head of R&D (руководитель отдела исследований и разработок) в Ciklum. Специалист по разработке систем машинного обучения с опытом работы в Сеуле (Южная Корея) в исследовательском центре.
Видео: Нейросети, искусственный интеллект, машинное обучение в украинском бизнесе
Содержание интервью по минутам
- 0:35 Карьерный путь специалиста по AI: КПИ, корейские разработки, Ciklum и должность СТО в американском стартапе
- 3:04 Простое объяснение технологии искусственного интеллекта
- 4:43 Бизнес применение технологии распознания визуальных объектов
- 6:52 Языки для работы с нейросетью и технические особенности технологии
- 8:39 В чем заключается лидерство и его математическая формула
- 10:08 Данные, которые украинская власть планирует предоставлять бизнесу и наиболее востребованная информация в мире
- 11:47 Информация, которая закрыта государством. Ответственность за использование данных (на примере medical data)
- 13:03 Чем вызвано такое активное развитие AI технологий. Почему AI технологии так слабо представлены в сфере медицины
- 15:26 Сервер под капотом Tesla и необходимые разработки для демократизации этого товара. Об автомобильном рынке в перспективе 5 лет
- 16:36 Украинские бизнес-разработки Scalarr на конференциях CVPR і NIPS. Для чего создаются инновации и какая роль бизнеса в этой сфере
- 18:51 Transfer Learning - адаптация нейросети для задач в других областях, распределение работ по первичному созданию сети и адаптивное переучивание
- 21:08 Готовые библиотеки для нейросетей и лицензирование данных
- 23:50 О Hadoop и sql - что, где и зачем применяется
- 26:30 Эволюция обязанностей программиста. Необходимые навыки для успешной работы
- 27:31 Какие преимущества от использования искусственного интелекта в бизнесе
- 28:18 Методология работы по проектам AI и зачем применяется классический waterfall
- 29:31 Кто в Украине покупает нейросети и как это сравнимо с иностранным клиентским портфелем
- 30:14 Сколько стоят проекты по AI, цена аренды мощностей, покупки серверов. Что влияет на цену, и причем здесь биткоины
- 31:44 Цена специалистов по AI у нас и в Лондоне и их наличие, формирование стоимости проекта
- 33:06 Почему бизнес еще плохо понимает зачем ему Computer Vision, и за счет чего развивается рынок АІ на примерах
- 34:03 За счет каких элементарных усовершенствований безупречное конкурентное преимущество в будущем для бизнеса можно создавать уже сейчас
- 35:56 Прогноз изменения в e-commerce. В каких магазинах мечтают покупать вещи занятые мужчины, и как уже продают в Америке
- 38:31 Как будет развиваться человек, когда нейросети начнут ему рекомендовать что делать, насколько им можно доверять и зависеть от них
- 40:19 Примеры сфер, где AI может сыграть злую шутку с людьми
- 42:15 Кто ответственен за развитие технологий человечества, инженеры или политики
- 43:07 video-detecting по людям - популярная игрушка, как она применима для бизнеса
- 44:45 Для чего понадобилось идентифицировали позы человека на видео для большого автомотива. Распознавание положений тела может спасать жизни
- 47:03 Инвестиционный банк задействовал искусственный интеллект в определении инвестиционной привлекательности, и нужны ли им теперь эксперты-люди
- 49:07 АІ активно используют во всем мире в качестве вычислительно-обрабатывающего мозга, а как с его воплощением в реальном теле в виде роботов
- 50:59 Когда человек начнет сливаться с техникой, вживляя себе чипы и превращаясь в биомеханизм, какую мощь он получит. И что будет с несогласными
Весь текст интервью
Всем привет! С вами Зосим Максим на канале "Perceptron", и сегодня мы в гостях у Бориса Працюка. Мы сейчас в UNIT.City. Погнали!
Карьерный путь специалиста по AI: КПИ, корейские разработки, Ciklum и должность СТО в американском стартапе
0:35
Привет!
Давай для наших слушателей, для людей, которые нас смотрят, ты немного расскажешь о себе, своем жизненном пути, как ты до этого дошел, до жизни такой
?
Как я дошел до этого коридора? Если долго говорить, то все началось с математического лицея, я 15 лет проучился и проработал в КПИ. Я учился в лицее, затем пошел - 6 лет - в КПИ, 5 лет работал на кафедре, писал там диссертацию. И параллельно работал. С 2004 года я начал работать сишником, как тогда говорили. Затем, на пятом курсе, мне предложили поехать в Корею, чтобы поделать исследования в Рендилабе. Так что я был в Сеуле, проработал там около 5 лет. И там, и удаленно, потом пошел в аспирантуру, закончил. А уж когда закончил, решил больше не выезжать, потому что предлагали поехать в Корею, продолжить там работать.
1:35Что ты там делал непосредственно?
Я там делал все, я занимался embedding, я там работал в IUT, но оно еще не называлось IUT. Различные сенсоры делал, различные приборы. В принципе, занимался обучением молодежи, коллег своих и т. д.
Уже когда вернулся, я работал в "Андроиде", был Mobile-разработчиком. И когда закончил, дописал свою диссертацию, защитился, решил никуда не ехать и попытаться найти себя здесь. Сменил компанию - ушел в компанию свою предыдущую, Ciklum, где я семь лет отработал. А после Ciklum, недавно, 2 месяца назад, я пошел в компанию Scalarr - это американский стартап. Я теперь CTO, и мы движемся вместе с биг-дата и искусственным интеллектом к мировому признанию
.
2:24Какие из проектов по искусственному интеллекту ты делал? То есть как ты попал именно в это направление?
Если подумать о компании Ciklum, то последние 4 года я был Head of R&D, и мы там делали очень много: мы делали computer vision, мы делали big data, в плане анализ табличных данных. Делали всевозможные R&D проекты, где мы смешивали анализ звука, алексы, google home, conversational commerce, когда ты разговариваешь, делали концепты смешанные IUT + conversational commerce. Короче, очень много проектов. Так чтобы быстренько сказать, какие мы можем делать, то надо сесть и рассказывать о каждом.
Простое объяснение технологии искусственного интеллекта
3:04 А если бы тебя спросили: "Объясни школьнику, что такое искусственный интеллект и ML, что бы ты ему рассказал?"
Это очень легко. Вот если взять ... это доска наша. Я всегда рисую так линию, и говорю: "Вот наш график, и это наши точки. Например, это покупатели, которые у нас будут покупать, а вот эти не будут. И нам надо провести линию. Каждый школьник может взять линейку и провести линию вот так. Разделить на 2 группы: купят - не купят. И теперь надо написать программу, которая проведет линию за тебя, и будет уметь проводить. Здесь данные могут смешиваться, выделяться в разные группы, кластеры. Программа искусственный интеллект должна проводить эту линию, разделять на группы и делать анализ. И это, в принципе, в двух словах о машинном обучении. Мы так же анализируем трафик и разделяем его на хороший трафик и плохой.
3:57 Это и данных касается, и изображений, и всего? Задача математически одинаково звучит?
В принципе, мы обучаем систему видеть какие-то паттерны. Если это разделение двух групп, это проведение простой линии. Если это изображение, то мы учимся распознавать всякие edges, градиенты в изображениях, видеть глаза. Если это звук, то мы обучаем нейронную сеть видеть паттерны в спектре, или еще в чем-то. То есть это всегда изучение данных. Мы берем данные и обучаем на этом нейронную сеть, мы балансируем эти коэффициенты и минимизируем функцию. У нас сходится, сходится, сходится, и когда она сошлась, мы можем затем додиктовать определенные паттерны.
Бизнес применение технологии распознания визуальных объектов
4:43 Мы все знаем кучу всяких задач, зачем это нужно: определение лица для соцсети и прочее. А зачем это нужно бизнесу?
Вы видели - на входе в UNIT.City стоит автомат, и у меня есть карточка. И они смотрят на мое лицо. И каждое утро, когда я прохожу - авторизуюсь. Я говорю, что я здесь работаю, я Борис, и вот это мое изображение. И сегодня, когда я вас проводил по этой карте, он сказал "неавторизированный посетитель", так как не совпадает лицо твое и то, что каждый день он видит. И это бизнесу нужно: это безопасность, это автоматизация процесса. Ты въезжаешь на парковку, и не надо будет иметь какого-то контроллера, который узнает драйвера, узнает его машину, скажет "Добрый вечер". Интеллект это сделает за него. По сути, автоматизация - это ускорение процессов. Если это производство мяса, то сейчас все знаем, кто нарезает это мясо - это человек стоит. Научить машину резать, как человек, тушу - легко. И она будет уже разделывать эту тушу без участия человека. А человек может читать книги, учиться, мечтать о чем-то большом.
5:54 Расскажи, на техническом уровне - что это? То есть как это происходит?
Технически мы берем большой датасет, мы берем много данных. Если у нас есть лицо, оно имеет определенные паттерны, есть глаза, есть нос, есть рот. И когда мы загружаем это большое количество изображений, по сути, мы изучаем, как выглядит лицо. То есть мы видим, что есть определенные овальные ниши для глаз, есть нос. И когда мы пропускаем через нейронную сеть эти изображения, по сути, изображение раскладывается в такой большой ряд этих входных инпутов, и мы запускаем. И нейтронная сеть запоминает, что если мы детектим лицо, то вот это имеет такой примерно pattern, это такое соотношение пикселей. Например: если мы видим собачку, или кошечку, или человека, мы уже знаем, что если там усы такие длинные, то это паттерн кошки, и нейронная сеть сразу увидит это.
Языки для работы с нейросетью и технические особенности технологии
6:52 Ты рассказываешь архитектурно на уровне квадратиков. А в общем, технически, что такое нейросеть? Вот я сижу, я школьник, и мне хочется начать ковыряться. Я хочу сделать первую какуюто нейросеть свою.
Технически это просто набор различных библиотек, которые позволяют организовать... это уже библиотеки с определенным набором алгоритмов, которые уже создали, и ты берешь просто конфигурируешь эту архитектуру, о которой я рассказывал, и начинаешь учить, учить... Как? У тебя есть данные на диске, и ты описываешь, как, в каких форматах эти данные подавать на вход нейронной сети, как контролировать обучение.
Это, по сути, такая библиотека, с уже существующими инструментами, которая позволяет быстро начать обучать нейронную сеть.
И надо знать Python. Если ты Python не знаешь...
А другие языки не подходят?
Чтобы я сейчас не обманывал, есть другие языки, можно это делать. Есть такой фреймворк Scala, но 90% - это Python. Можно что-то в Матлабе делать. MatLab - это одна из первых систем, которая была создана для ученых, и она создана учеными для ученых. Там свой язык, но они сейчас тоже много делают для... но 90% мира - это Open Source библиотеки, которые позволяют обучать нейронную сеть. Уже можно дома сесть и начать обучать нейронную сеть.
В чем заключается лидерство и его математическая формула
8:39 Расскажи, эта формула математическая лидерства откуда взялась?
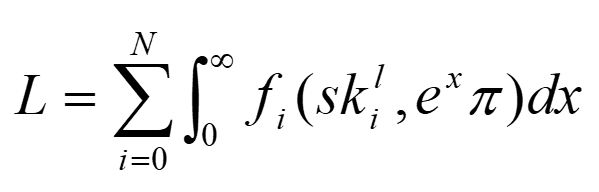
Знаете, я очень люблю математику, и я команду свою спросил: "Кто я такой? Зачем я вам нужен вообще? Project Manager нужен, чтобы менеджить, QA - чтобы тестировать, девелопер - чтобы писать код, ученые - чтобы находить гипотезы. Зачем вам Head или лидер?» Я так загрустил немного. Говорю: "Может, я с вами буду писать код?" Они говорят: "Смотри, ты нам нужен, потому что без тебя как-то оно не идет". Я тогда задумался, а в чем же суть лидера? Почему раньше люди шли в бой за командиром, и вообще, как это работает? Начал анализировать, и понял, что лидер - это очень простой человек. Человек, который объединяет сильные стороны своей команды, делает из команды такой squad (отряд), который пробивает новые стены. То есть с хорошей командой.
Математический смысл есть?
Математический, если перейти от того, что лидер собирает команду и пробивает стены с этой командой, то вот здесь сумма: это Н - количество людей - цифра людей, которые имеют в себе какую-то функцию, которая зависит от skills и experience - это его навыки и опыт жизненный. Учитывая, что X у нас переменная по dX, то от ноля до бесконечности, потому что мы живем, и это время, и мы все время накапливаем опыт и навыки. То есть лидер - это человек, который объединяет людей с разными скиллами и опытом.
Круто! Ты это сам? Не подсмотрено?
Нет-нет! И еще здесь есть такие баталии, правильная ли она, но...
Данные, которые украинская власть планирует предоставлять бизнесу и наиболее востребованная информация в мире
10:08 Мы говорили по поводу обучения на датасетах. В своем выступлении на i-Forum 2019 ты показывал слайд, там есть прямо название, если я правильно помню, "COCO и Mapillary", то есть все это названия датасетов непосредственно?
"COCO - это такой датасет, который можно использовать для тренировки ваших нейронных сетей. Что с ним можно, благодаря ему можно делать? Можно делать object detection, но уже object detection происходит не рамочкой, а мы делаем как бы сегментацию. Мы многое можем делать. И что это нам говорит? Новые технологии убивают старый подход ".
Это отдельные прямо сейчас ниша и рынок, который образовался в результате нейросетей?
Смотрите, сейчас такая трансформация в мире, все бьются за данные. Вот был на прошлой неделе Open data forum, наша украинская новая власть, с правилами, люди, которые это хотят продвигать, они говорят: "Мы хотим понять, как дать данные бизнесу, чтобы они делали больше бизнеса". Потому что во всем мире есть медицинские данные открытые или закрытые, есть телекоммуникационные, различные типы данных, и государство их предоставляет, или бизнесы их продают. И мы выходим на уровень, когда, имея правильный датасет, имея правильных датасетистов, мы можем их объединить и получить просто бизнес на пустом месте. Вот поэтому есть рынок данных, и это уже давно в мире он существует, где продают датасеты.
Информация, которая закрыта государством. Ответственность за использование данных (на примере medical data)
11:47Насколько я знаю, на сегодняшний день уже есть более 140 открытых реестров, которыми можно пользоваться, или они что-то новое хотят вносить?
Они хотят больше добавлять и спрашивать у бизнеса, какие датасеты нужно дать, что еще можно добавить, чего не хватает? Сделать либерализацию. Чтобы это было открыто, чисто, понятно. Если я взял эти датасеты, какую я ответственность несу? Потому что если это medical data, то как я их буду использовать?
Medical как раз, по-моему, не открыты сейчас.
Вообще нет этого. А в Medical - это топ 1 в мире, по Medical-data, по анализу MRA-снимков этих рентгеновских, по нахождению опухолей и т.д. И наши специалисты в Украине - одни из лучших в мире, они делают хорошие публикации, но датасеты они берут мировые.
Там они открыты?
Там есть определенные университеты, которые для research открывают маленькую часть. Вы понимаете, если нам дали 1%, и наша нейронная сеть показывает 99-95%, то если нам бы дали все датасеты, то мы бы получили 99,99999...%, и это было бы безошибочно. Это точность.
Чем вызвано такое активное развитие AI технологий. Почему AI технологии так слабо представлены в сфере медицины
13:03 Насколько я знаю, процент определения с помощью человека, когда он смотрит, гораздо ниже. Почему человечество до сих пор в промышленных масштабах не использует это?
"В 12 году что произошло? Был такой ImageNet Challenge, когда люди пытались... писали алгоритмы для распознавания картинок. Это выглядело следующим образом: вот, например, container ship, - вы видите, там такая баржа с контейнерами - они пытались угадать, что находится на изображении. И вот в 12 году AlexNet, кажется... Кто помнит историю? Они сделали на нейронных сетях решение, которое по качеству распознавания было, кажется, на 10% или там на 7 лучше, чем все предыдущие методы. И качество распознавания каждый год, то есть error rate, падает, и качество повышается. То есть сейчас это 98% или 99 точность. Почему так? Потому что появились GPU" (GPU - graphics processing unit – графический процессор). Начали заниматься deep learning, нужны стали GPU. Компания NVIDIA быстренько переформатировала игровые GPU в deep learning, начали давать мощность. Больше мощности - быстрее итерации, оно начало ускоряться. Через 7 лет, сейчас, у нас уже ездит Tesla, которая сама ездит. Это за 7 лет. Research (исследования) шли 25 лет, но вот такой экспоненциальный прорыв пошел благодаря...
14:41 Почему так? Ты на том же форуме показываешь слайд, это не новый хайп, не нова технология?
Она уже была, не было датасета. Знаете, сколько видео с фотографиями сейчас люди загружают в Google и в Фейсбук? Миллиарды! И это датасеты. И поэтому эти датасеты пропускаются через кластеры GPU, и мы получаем новые нейронные сети, новые статьи, новые библиотеки, которые позволяют тренировать. Пришло время, я бы сказал. Потому что технология ускорения этого обучения GPU позволила перейти и учить не 9 часов нейронную сеть, а 5 минут. Ты делаешь не сутки интеграцию, а за день 25. И оно начало ускоряться. Просто пришло время.
Сервер под капотом Tesla и необходимые разработки для демократизации этого товара. Об автомобильном рынке в перспективе 5 лет
15:26 Ты говоришь, что по поводу распознавания для Tesla, что сейчас все равно сервер стоит в машине.
Пока что да.
И в том числе в Tesla стоит сервер.
Если так подойти к стенду там, на конференциях, где они показывают NIPS. Они говорят, что действительно сейчас пока открывают капот, и там стоит большой мощный сервер, с большими видеокартами, которые потребляют много энергии - это концепт. Каждая компания: Тесла, NVIDIA работает над таким чипом, который будет позволять с малыми энергозатратами обрабатывать этот image puzzle. Лицо детектить - это уже легко, это было сложно 10 лет назад. Там был такой вот (огромный) сервер, теперь можно делать на телефоне Face-ID. То есть они все оптимизировали. И теперь следующий шаг еще пять лет - и это будет Production Rate, и все машины будут иметь систему мониторинга столкновений, приближения, автоматической остановки, если она видит. Очень ночью помогает, потому что ты не видишь, а камера видит, и можно очень много сохранить жизней.
Украинские бизнес-разработки Scalarr на конференциях CVPR і NIPS. Для чего создаются инновации и какая роль бизнеса в этой сфере
16:36 Ты упоминаешь 2 конференции масштабные, это CVPR (ежегодная конференция по компьютерному зрению и распознаванию образов) и NIPS (конференция по машинному обучению и особенностям нейробиологии, которая проводится каждый декабрь). Ты был на обеих, как я понял. Расскажи, о чем и как вообще.
Я как хороший лидер не ездил туда, потому что поехать туда очень дорого, я свою команду туда отправлял. Они были несколько раз и на CVPR, и на NIPS. Даже в этом году на CVPR команда делала презентацию, воркшоп. Они сделали интересный paper... Это уровень. Вы понимаете, что в Украине уже делаются такие исследования, что в отношении любого объекта они делали prediction (предсказания): какой там скелет. Для любого объекта они рисовали структурные грани, где у него скелет, на чем все держится. Это, по сути, центр масс. Это очень прикольно.
Не только для человека?
Для любого объекта, для яблока, для стола. То есть они могут нарисовать, что в нем есть несущее, центр. Это интересный research, и они просто проводили воркшоп и объясняли, как они это делали, и у них был час на представление.
Для чего? В бизнес-задачах как ее можно использовать?
А смотрите. Здесь очень интересно. Любой человек, который занимается АІ, он занимается ради АІ - ему нравится эта штука, а уже задача бизнеса - это моя была задача - понять, как эти paper-ы, все свои научные достижения перенести на бизнес.
Мы делали проект: мы детектили апельсины - автоматический подсчет апельсинов на дереве. Человек никогда не подсчитает очень точно все апельсины. Одно дерево, второе, а там их миллионы - 1,6 акров.
"Приходим к клиенту и говорим: "Боже, 83% - это так плохо!» Он говорит: «Пацаны, это круто! Это же 83! 75 - у человека, а у вас 83, так что вы молодцы".
Это только искусственный интеллект, только камеры. И если не будет этих research-ей, которые просто позволяют качественно детектить скелет, форму и т.д., то не будет этих лего-кубиков, из которых собирается бизнес-решение. И ученые делают вот такие исследования, paper ради paper, а затем приходит бизнес-компания, которая имеет свой департамент, и делает из этого value.
Transfer Learning - адаптация нейросети для задач в других областях, распределение работ по первичному созданию сети и адаптивное переучивание
18:51 Ты говорил еще об одной технологии - transfer learning, когда у нас есть обученная нейросеть, например, распознавать то ли апельсины, то ли яблоки. У нас апельсинов нет, поэтому применим это к грушам.
У меня сразу возник вопрос: сама технология и подход - он применяется... Яблоко, груша, апельсин между собой похожи, а если мы говорим о детектинге: вот у нас есть нейросеть, которая яблоки распознает. Это вообще применимо к лодкам?
Подход очень прикольный чем? Что мы тренируем нейросеть, потом мы сохраняем ее конфигурацию, все эти коэффициенты, для того чтобы мы ее, например, натренировали детектить стол и пуфик, на чем мы сидим. Они были определенной формы, определенных моделей. Мы смастерили пуф, и человек может сидеть, а мы хотим перейти на стулья. И мы берем просто эту модель, которая уже научилась. Что значит модель? Она научилась видеть эти грани, она научилась видеть формы, что там мягкое. И мы берем и переучиваем, то есть эту титаническую работу, которая была какими-то инженерами проведена, мы ее немножко дообучаем, немножко корректируем. Это как научить видеть машины, и эта модель будет видеть машины: колеса, крышу. А потом нам надо видеть, например, только одну модель. И мы берем эту вот базовую нейронную сеть, которая очень хорошо распознает машины, автобусы и т.д., и дообучаем на specific business issue, специфику зон.
Этот подход Transfer Learning работает вообще круто для бизнеса, но сможем ли мы, если мы тренировались на апельсинах, видеть машину? Пожалуй, нет. Потому что очень много там надо будет переучивать, и когда мы переучим, то от той первоначальной нейросети ничего уже не останется, она вся переучится.
Transfer Learning хорошо подходит, когда у вас есть похожие задачи. Институт научный research сделал 90% тяжелой работы, отдал это бизнесу, а дальше я видел очень крутую работу у дизайнеров: нейронные сети, которые распознают мебель. Все, что они сделали, - они добавили еще туда кое-что и начали раскрашивать эту мебель. Они это очень быстро сделали: базовая модель была, и они дообучили ее своими работами, и оно начало раскрашивать стены, вешать картины, и это уже не один год работы, а месяц.
Готовые библиотеки для нейросетей и лицензирование данных
21:08 По поводу "институт сделал research", ты упоминал 26 разных. Кажется, это Стэнфорд. Как они это предоставляют? Это просто Open Source библиотека, которой пользуется, кто хочет?
Да, там есть лицензия, во всем мире очень важна лицензия. Потому что, если, например, вы построили бизнес, никто этого не увидел, вы начали расти, и прибыли тоже. И когда у вас будет несколько миллионов, на вас просто подадут в суд, и эти деньги пойдут в Стэнфорд, потому что вы нарушили базовую лицензию. Как узнать? Очень легко. В Европе и в Америке есть специальные институты, которые делают аудит вашего решения, и вы должны предоставить эту информацию. То есть если ты начинаешь делать что-то, связанное с AI, лучше очень сильно уважать лицензии. Поэтому для research, для того, чтобы посмотреть, работает ли этот концепт, подходит, когда начинаете делать бизнес-решения, нужно самому собрать свой датасет и переобучить нейронную сеть на своем датасете. Потому что только так он будет legal решением.
А то, что предоставляет Стэнфорд, это не для коммерческих проектов?
Там надо читать. То, что для обучения, для научных целей - 100%... Там всегда мелким шрифтом написано "for personal use only". Потому что они для того, чтобы обучать студентов, новое поколение работать с AI, очень круто, а вот для commercial use, когда ты хочешь на этом заработать, здесь уже вопросик, сколько effort-ов было инвестировано в эту систему. И надо платить. Я это не смотрел, честно.
22:53 Ты в выступлении рассказывал о заказчике с инвойсами, о process automation. С какой задачей он вообще пришел?
В принципе, он пришел с другой задачей. Это был у нас такой воркшоп. У него задача была сделать следующий модуль системы, он давно уже работал с нами, и надо было ему сделать какой-нибудь модуль. А потом он говорит: "О, а я еще хочу там аналитику. Можно мне сделать там email?»А я говорю:" Какие у вас там параметры, как вы Трекате? "Он говорит:" У меня один параметр, в email: открыто / не открыт. Можно мне сделать data science?» А я говорю, мало параметров, мало данных, нет датасета. То есть надо трекаты, когда он открылся, когда закрылся, открывал ли он еще раз, сколько раз он возвращался к этому документу. То есть для того, чтобы построить, заменить человека на персонализированный алгоритм, нам нужно иметь поведение человека. А вот поведение трекаты можно именно этими ивентами, событиями.
О Hadoop и sql - что, где и зачем применяется
23:50 Через какое-то время он к вам вернулся с датасетом?
А он никуда не ушел. Мы ему дали рекомендации, он пошел собирать этот датасет. Мы говорим, полгода нам где-то хватит, чтобы начать делать те все продукты по view concept. Говорю, иди собирай, потом возвращайся, и мы будем тебе делать.
И вернулся он с SQL. Расскажи, пожалуйста, для тех, кто не понимает, в чем разница. Ты упомянул там Hadoop и SQL. В 2 словах, в чем разница, что это и зачем?
В принципе, это неплохо. SQL (structured query language) - это такой специальный язык, которую ты можешь писать и из базы данных вынимать свои данные.
Как раз об SQL, наверное, знает большинство людей, а вот о Hadoop - половина не знает.
(Hadoop - проект фонда Apart software foundation. Свободно распространяемый набор утилит, библиотек и фреймворков для разработки и выполнения распределенных программ, работающих на кластерах из сотен и тысяч узлов).
Почему сейчас немножко все поменялось? Если раньше нам хватало одной базы данных, то когда наших данных становится миллион, возникает уже идея перестройки индекса. Это догма. Для миллиона нормально. А миллиард? А 10 миллиардов? А если 10 миллиардов в час данных? Мы уже не можем применять старые подходы, поэтому возникает Hadoop - это такая экосистема параллельных вычислений. Мы можем делать Ноды - это отдельный сервер - и легко масштабировать систему, она вся распределена. То есть там есть HDFS - файловая система. Потому что мы не всегда получаем данные как запись в базе данных. Иногда нам приходят invoices - это физические pdf, excel, и их надо где-то складывать. Представим себе глобальную компанию, которая есть в Америке, в Украине, в Японии. Мы получили invoice в Японии, а процессинг происходит, например, в Америке. Нам нужно синхронизировать все эти три хранилища, и это все делается автоматически.
Есть такая HDFS-система (hadoop distributed file system) - она распределена, то есть ты положил, она автоматически на все ноды сделала копию. То есть ты работаешь с файлом, но где физически он находится, ты не знаешь. И раньше было как? Почему это важно? Потому что меняются подходы к программированию. Раньше ты мог себе на компьютере поднять базу, на своем лэптопе, локально это протестировать, затем протестировать с прод-базой, вылить и т.д. Сейчас это изменилось. Учитывая эту hadoop децентрализованную систему, все стало "decentralized". Все приходит в Docker, в Kubernetes. Docker - это контейнер, в который заворачивается софт, Kubernetes - это софтвер, который менеджит все эти контейнеры. И, представьте себе, это могут быть тысячи этих контейнеров, они поднимаются, схлопываются, данные летают, поэтому DevOps нам очень сильно помогает в этом.
Эволюция обязанностей программиста. Необходимые навыки для успешной работы
26:30 Для программиста, который это делает, что изменилось?
Просто разные tools появились. Он начинает работать с Hadoop, он пишет spark job-и. Spark - это такой framework, который там есть, и можно писать на Java, Scala, Python. И ты пишешь. Раньше ты писал SQL запрос, а теперь ты пишешь spark job. Это алгоритм, как ты хочешь извлекать данные, и ты можешь написать процессинг - берем файл, парсим его, складываем в какую-то базу. Берем Twitter-комментарии, парсим, складываем в базу. Например, если берем какой-то файл, и не хватает данных, ищем, где и как заполнить эти данные. Например, Борис Працюк, у меня пропущенный телефон. А у нас есть 10 source-баз, где можно поискать Бориса Працюка, и найти там. То есть делаем, минифицируем датасеты, чтобы было уже все заполнено, чтобы можно было тренировать нейронную сеть.
Так что изменились инструменты - очень много их появилось.
Какие преимущества от использования искусственного интелекта в бизнесе
27:31 В итоге какой process automation у этого клиента вышел? Результат этого проекта?
Сказать так откровенно не могу, там же многое под NDA (non-disclosure agreement – cоглашение о неразглашении информации). Знаете, когда спрашивают, расскажи нам результаты любого AI проекта, ты сразу думаешь, а не расскажу ли я какие-то свойства алгоритма или что-то такое, что потом придут ко мне и скажут: NDA...
В двух словах: у него получилось. Я не знаю, кстати, цифру финальную, насколько там что сократилось. Есть в других проектах, там какие есть бенефиты, на сколько, на 30% сокращались затраты на колл-центр. Например, у клиента, мы ему чатбот делали, и он внедрил, и у него уменьшился load колл-центра - это до миллиона долларов в год.
Методология работы по проектам AI и зачем применяется классический waterfall
28:18 Ты рассказывал, что вы делаете DL is a service (Deep Learning is a service), но при этом на следующем же слайде, как выглядит структура вашего проекта, то я для себя увидел такой классический waterfall в какой-то стадии. Объясни, что это такое?
Сервис мы делаем для клиента, а как он выглядит внутри - это те стадии, которые мы делаем, когда мы приходим к клиенту. Но для клиента - ему вообще неважно это знать. Он всегда спрашивает: "А что под капотом? А как вы это будете делать?". Никто не покупает так: сделай мне deep learning, сделай мне AI, и вот - на тебе! - миллион. Нет, все спрашивают: как вы будете делать, а как это интегрируется с нашим бизнес-процессом? Очень много вопросов. Поэтому, получается, для клиента у нас было несколько кейсов хороших. Пришел клиент и сказал: "У меня есть бизнес проблема", дал данные и ушел. А через два месяца мы дали ему нейросеть, которая решает его бизнес вопросы. И мы ему не показывали ничего: ни эти графики, ничего. Он купил as-is. Это был очень прикольный кейс. Другой клиент, очень многие клиенты, кстати, спрашивают: «А как это будете делать? А как у вас security?» Поэтому был такой график waterfall.
Кто в Украине покупает нейросети и как это сравнимо с иностранным клиентским портфелем
29:31 Если мы говорим о клиентской базе, то сейчас это больше европейский заказчик, или украинские заказчики уже тоже начинают идти к этим данным?
У нас был опыт с украинскими клиентами. Было 23 presale, это был агросектор, мы хотели сделать агро-campaign. Все говорят "агро в Украине на хайпе". Мы проговорили с 23-ю клиентами из Украины, это крупные холдинги, маленькие холдинги.
Один мы провтыкали, мы не успели к deadline, мы не успели подать наш estimation (оценку), потому что мы ее вовремя не получили, потому что они забыли нам написать, и мы не успели. Там был бы проект, это я знаю.
А эти 22, которые мы проиграли, - это когда мы доходили до pricing, потому что 25 баксов стоит час сервера в cloud-е, чтобы тренировать. Тренировать надо 24/7 месяц-два. Вы можете посчитать, сколько это стоит. Я даже не говорил, сколько стоит наша работа, наши знания о том, как работать с нейронной сетью. Я просто сказал, сколько стоит инфраструктура.
Сколько стоят проекты по AI, цена аренды мощностей, покупки серверов. Что влияет на цену, и причем здесь биткоины
30:14 А сколько приблизительно стоит? И даже это их пугает?
Просто чтобы пойти в Амазон взять машину или купить машину, сервер – 150 000 долларов. Нет таких денег...
А за счет чего это все? За счет того, что там очень видео сильное? Сервера для ERP-систем стоят гораздо дешевле.
Да. Потому что, когда ты тренируешь нейронную сеть, нужен GPU (graphic processing unit). А GPU, когда начали майнить биткоин, эти математические операции очень хорошо ложатся на GPU. И выкупили весь, все выкупали видеокарты. Потом стали делать больше специализированных, более дорогих, они очень хорошо подходят, они для майнинга плохие, а для Deep Learning они просто... Там и кэша больше, и видеопамяти, и RAM на сервере, короче, специальные серверы.
Последние серверы NVIDIA продает за 400 тысяч долларов, но она их не продает маленьким компаниям, они говорят: "Вам они не нужны, это надо для Uber, Tesla, которые тренируют эти миллиарды картинок, и им это нужно. Вам не нужно". Но все равно же, хайп есть, и купить этот GPU-сервер - это проблема.
Цена специалистов по AI у нас и в Лондоне и их наличие, формирование стоимости проекта
31:44 Хорошо, а сколько может для заказчика стоить сам проект? Мы не говорим о железе. Железо - это основные средства, мы можем их купить-продать.
Такой маленький, маленький проект, просто показать, будет ли вообще работать идея – 50 тысяч долларов.
Это ничего не делали... Чтобы вы понимали, есть уровень зарплат. Мы сейчас в глобальном мире девелопмента находимся. Украина значительно дешевле с точки зрения ресурсов, но программист в Лондоне, который занимается Deep Learning, стоит 300-500 тысяч долларов в год - это его зарплата.
Это выше на полтора по рынку, получается.
Да, есть там средняя зарплата 150-200 тысяч, а у них X2.
Почему так? Потому что их очень мало, их 0,3% от всей общественности, этих девелоперов. И, я говорю, 7 лет только рынок такой существует.
Почему бизнес еще плохо понимает зачем ему Computer Vision, и за счет чего развивается рынок АІ на примерах
32:41 А есть какая-то цифра по поводу дефицита этих специалистов?
Я знаю, что она есть, найти хорошего Deep Learning инженера очень сложно. Хорошая новость - все сейчас пошли туда учиться, очень много онлайн курсов, многие переучиваются. И я не видел такой статистики, по сути, не искал, мне не очень интересно было. Но дефицит есть, но нет еще такого смертельного дефицита, потому что бизнес еще не раскачался, бизнес еще не полностью понял, зачем ему этот Computer Vision.
Потому что все, кто занимается Computer Vision, плохо понимают бизнес. Они там просто делают это, делают, а потом - бах! - и взлетает какой-то стартап. И все спрашивают: "Как так случилось?" А он говорит: "Ну, просто занимался, занимался..." Есть такие VideoGorillas из Украины, они из маленького Video Resolution делают 4K, а сейчас все 4K имеют телевизоры, и старый фильм какой-то голливудский они делают 4К.
Олесь нам на прошлой неделе рассказывал.
Вот видите, как я комплимент им (сделал)! Вот когда Deep Learning, когда их тренинг превращается в крутой бизнес. И так очень часто бывает. Хорошо, что у них там CEO разбирается, и он это правильно продает. Но очень многие инженеры занимаются Deep Learning, a бизнес не обращает на это внимания, он еще early stage. Это еще идет адаптация. И здесь кто первый запрыгнет, тот и молодец.
За счет каких элементарных усовершенствований безупречное конкурентное преимущество в будущем для бизнеса можно создавать уже сейчас
34:03Ты думаешь, что это создаст безупречное конкурентное преимущество в будущем для бизнеса, который это будет иметь?
Я считаю, что да, если у тебя нет системы RPA (robotics process automation), ты умираешь от этой рутины на работе. То есть даже если ты сделаешь систему Чат-бот, которая будет отвечать на вопросы. Вот представьте: корпорация 5 000 человек, и человеку нужно что-то найти. Он как идет? Там есть такое меню (огромное) системы 35 - 40 штук, и он идет туда и ищет. Как бы вы хотели? Вы хотели открыть чат: "Бот-помощник, у меня такая-то проблема, я не могу заполнить какой-нибудь квартальный report для такого-то процесса". Он говорит: "Вот тебе link, вот тебе report - заполняй". Ты не тратишь день на поиск. Я реально знаю, о чем говорю, мы можем потратить 2-3-4-5 часов. А еще человек, который отвечает за эти репорты, в отпуске. Прекрасно.
35:05 Да, по статистике, 35% времени - это поиск и переструктурирование информации.
И именно это будет давать бизнесу рост, то есть кто первый адаптируется, тот будет уже экономить early stage. Потом - все. Это будто все перешли на мобильные телефоны.
35:18 То есть это не только о поведенческом анализе клиентов, это даже о внутренних процессах.
Да обо всем. Смотрите, веб-сайт. Ранее сайт грузился так (медленно) на модеме, и это было "О Боже, у меня есть веб-сайт!" В 2000-ных все хотели иметь свой веб-сайт, сейчас все хотят иметь свой онлайн-шоп. Или уже он есть, там e-commerce. Потому что все в мобильных, 90% детей - в мобильном. Нужно адаптировать mobile version сайтов. Понимаете, 20 лет назад ничего этого не было. Сейчас началось, появился АІ.
Прогноз изменения в e-commerce. В каких магазинах мечтают покупать вещи занятые мужчины, и как уже продают в Америке
35:56 Как, по твоему мнению, изменится e-commerce с внедрением этих технологий?
Он уже меняется. То есть сейчас, посмотрите, Amazon, eBay, Alibaba - все эти магазины инвестируют миллионы, я бы сказал, миллиарды в системы prediction поведения клиента - что он будет делать, что ему предложить, - и это очень классно работает. Потому что в Netflix показали, как оно работает. Вот ты посмотрел 1 фильм, и это настолько удобно! Сколько раз ты спрашивал: "Что бы мне посмотреть, чтобы я был доволен?» И я поставил эту систему, посмотрел 1 фильм, а мне порекомендовали "тебе понравится". После этого мне Netflix порекомендовал 10, которые мне понравились, и пошла лавина. И он начал рекомендовать мне контент фильмов, которые, я даже в жизни не мог подумать, что мне понравятся, и теперь нет проблем с тем, чтобы "что-то интересное посмотреть" для тебя, именно для тебя. Это круто, потому что e-commerce уже трансформировался, и все эти prediction-и, они делают так, чтобы твой контент... Вот я ненавижу ходить по магазинам. Почему? Потому что одежды много, а то, что подходит мне, - это очень трудно найти. Я мечтаю просто о том e-commerce, когда я захожу, и он, она, оно знает, что я ношу, какие я люблю стиль, вещи и т.д. Оно мне пакует, все ко мне домой приезжает, и все мне подходит, я не сдаю назад. Это экономит мое время, e-commerce на этом зарабатывает, я их постоянный клиент, я никуда не ухожу. И угадайте, у кого я буду покупать одежду? У тех, кто сделает эту систему.
Если у тебя есть эта система, у тебя покупают. Нету системы - никто не будет ходить по твоему сайту, искать описание, читать - это не нужно. Даже чтобы описание писать, контент-менеджер не нужен. Надо иметь вид вещи, размеры, автоматический алгоритм подбирает человеку, рекомендует. Что делают в Америке? Им дешевле, не спрашивая, привезти больше вещей, и ты потом сдашь назад бесплатно. И там 10/15 процентов повышения продаж, потому что когда они привезли домой вещи, ты уже думаешь: "Мне не нужно, но отдавать обратно не хочется - оставлю". И это тоже такая стратегия. Так что e-commerce меняется, и чем больше будет алгоритмов, тем будет ускоряться и будет меняться.
Как будет развиваться человек, когда нейросети начнут ему рекомендовать что делать, насколько им можно доверять и зависеть от них
38:31 Так, у нас осталась еще пара вопросов. По-моему, нам эта локация не подходит.
Так, ну, теперь нормально.
Вот по поводу постановки различных там роликов или рекомендаций для одежды. Меня в этом всем вопросе пугает одна вещь: не получится ли так, что мы потеряем наше культурное развитие? Нам рекомендуют то, что нам одевать, что нам смотреть. И выходит, допустим, режиссер, совсем по-другому смотрит на мир. Как Netflix порекомендует тебе посмотреть этот самый? Ты по-прежнему будешь смотреть один и тот же контент. Не маргинализирует ли это человечество в своей культуре?
Знаете, это сейчас такой тренд в мире - называется этика нейронных сетей и машинного обучения: как и насколько мы можем интерпретировать работу этих алгоритмов. Все укладывается в этот тренд, то есть насколько мы зависимы будем от этих алгоритмов? Я не могу ответить на этот вопрос, потому что он очень философский: что будет, если искусственный интеллект начнет нам все рекомендовать?
Давайте проведем аналогию, что телевизор - это тот самый канал влияния информации на наш мозг, как и искусственный интеллект, который нам что-то рекомендует. И как появление телевизора, этих всех теле-, медиа штук изменило нашу жизнь? То есть мы начали проводить выборы по-другому, начали влиять на сознание людей. Что им показывают, в то они и верят. Тот же алгоритм, если он будет рекомендовать там что-то смотреть, человек будет... 95% не относятся критически к информации - они будут делать то, что им скажет алгоритм. Поэтому, к сожалению, здесь будут злоупотребления и плохие парни, которые будут это делать.
Примеры сфер, где AI может сыграть злую шутку с людьми
40:19 Пример?
Политики, которые будут влиять на сознание, чтобы быть избранными.
Продажи некачественных товаров или товаров, которые вам нужны. Например, изобретение чего-то такого, вывода его в тренды. Ну, не знаю там, карандаши какие-то, без чего, по сути, можно жить. Знаете, есть такой термин сейчас - "потребительство". іРhone - хороший пример. Все время выходит новый iPhone, и просто это целая истерия, это очереди в магазинах... Это как раз хороший пример, когда навязывают, что тебе надо покупать, покупать, покупать. Человеку это не нужно, он может быть счастлив без этого, так что примеры...
Пропаганда. Ты можешь взять какую-то страну, в истории уже такое было, когда какой-то африканский народ довели до того, что они верили в колдунов, они вырезали целые зоны, прибегали туда с мачете и убивали людей, потому что им сказали, что это колдуны, маги какие-то. И они в это верили.
Но технологии становятся очень мощными, и если мы будем применять АІ, искусственный интеллект и анализировать поведение людей, то им можно навязать любое мнение, и это очень опасно.
41:38
Еще один очень опасный тренд - это оружие. То есть Илон Маск и ученые собирались в прошлом году, и они подписали меморандум о том, что искусственный интеллект никогда не должен использоваться для оружия. Но сейчас он используется, то есть сейчас эти же Javeline ракеты, они видят танк, они его распознают, и они в него попадают.
Имеются в виду более автоматизированные системы, которые будут автоматически наводиться, автоматически уничтожать людей, - это очень опасно, потому что это почти невозможно контролировать. Потому что алгоритм не распознает, свой или чужой.
Кто ответственен за развитие технологий человечества, инженеры или политики
42:15 И это следующий челлендж. Кто участвует, то есть как ты считаешь, это задача инженеров, или все-таки политиков?
Технология - это всегда просто набор ноликов и единичек. Это человек перед ноутбуком, который тренирует ту сеть, или делает технически. Это как инженер - она реализует желание, закручивает ту гаечку. А кто уже выстраивает стратегию, как использовать этот прибор, или как интегрировать его в социум, - это уже вопрос. Это уже вопрос к политикам, к государству и т.д.
Мне кажется, что должна быть глобальная стратегия государства на внедрение искусственного интеллекта. Вот в Китае стратегия: они в некоторых провинциях ввели этот personal score, по которому тебе дают скидку на билет на поезд, если ты хорошо себя вел. Но это же вопрос, что считать хорошо.
video-detecting по людям - популярная игрушка, как она применима для бизнеса
43:07 Подходя к этой теме, video-detecting по людям, там две технологии: раньше было bounding boxing - мы определяли, где в изображении там вообще человек находится. Сейчас все больше object-detecting, который интересует. Почему и где это в бизнесе применяется?
Раньше это было просто найти в кадре, что где-то в этой зоне этот объект. То есть не было важно, где его зона, если он ищет человека, он находит. Если два человека рядом - он их находит, что это люди. Или человек, и он такой большой квадрат рисует. И было неважно... Мы знали, что в кадре человек. Теперь важно. Если, например, AmazonGo - магазин, где человек берет товары с полки, надо трекаты, что это вот этот человек – точность. Когда мы видим, что это рука вот этого человека, и она взяла этот товар, у него было interaction - взаимодействие этого человека с этим товаром. И тогда можно протрекать, что он его взял с полки, положил себе в корзину, и это надо оплатить. Повышение точности дает бизнесу возможность... То, что невозможно было сделать раньше, например, сделать автоматический трекинг покупок и т.д.
То же самое на площади: у тебя есть много людей, и нужно каждого отдельно посчитать, или выделить, или надо посчитать, сколько мужчин и женщин, или подростков и т.д., любую аналитику собрать. Для того, чтобы понять, что в этом cloud-е происходит, невозможно это сделать по старой технологии. Поэтому как раз сегментация, вырезания контуров человека или лица...
Для чего понадобилось идентифицировали позы человека на видео для большого автомотива. Распознавание положений тела может спасать жизни
44:45 А еще в выступлении ты говоришь о том, что хайп текущий - это не просто определить человека, а определить его позу. А для чего?
Если, например, мы делали секретный проект, не буду говорить, для большого автомотива. У них проблема - конвейерная линия. Они собирают машины, и остановка на минуту конвейерной линии стоит этому гиганту 1 миллион евро. У них есть факт, что за месяц она останавливается там н-количество часов или раз. И они говорят: "Хорошо, у нас есть факт, почему это произошло, и человек, который это сделал. Он идет на специальную процедуру, там описывает, что было, для того, чтобы мы разобрались, правильно ли все работает, или что-то там напутали". Но человек всегда боится, что его уволят, он дает ложную информацию. Кстати, еще GDPR privacy, то есть нельзя ставить камеру. Есть специальные технологии, в которых там можно использовать радар, камеры и научить этот радар видеть человека как объект, и потом распознать его позу, что он делал. И ты можешь тогда записать 24/7, как человек собирает машину, скручивает, что происходит, и тогда будем иметь вот такую полную картинку, что случилось, что было за час или два до того, сколько он работал, может, ему там штаны жали, и ему было почему-то неудобно. И можно тогда понять причину, почему так произошло. И для бизнеса это полезно.
Например: если есть какая-то поза bus driver-а, если он начинает засыпать, у него меняются движения, и это не только о позе, а о поведении объекта. Например, наклоны головы очень незначительны. Но если мы видим не просто голову в кадре, она так же, как была. А если она начинает так падать, то человек засыпает. Или глаза закрываются. Эти маленькие детали уже можно воспроизвести, и они значат, что через десять минут он полностью заснет, и будет авария. И (нужно) разбудить и остановить машину или что угодно.
Инвестиционный банк задействовал искусственный интеллект в определении инвестиционной привлекательности, и нужны ли им теперь эксперты-люди
47:03 На 20 минуте выступления ты рассказываешь, как один инвестиционный фонд решил применить нейросети для определения прибыльных или неприбыльных стартапов. У меня сразу возник вопрос: у тебя есть какой-то паттерн, который они хотят найти? Ты рассказываешь о том, что они вот, несмотря на описание, могут это сделать, то есть это надо переложить на математику.
У меня сразу возникает вопрос: из-за того, что они сейчас не могут задетектить все такие стартапы, поэтому их экспертиза человеческая ценна.
Как только нейросеть все эти стартапы задетектит, не получится ли так, что из-за того, что они все задетекчены, они перестанут быть такими прибыльными, перестанут быть уникорнами в итоге?
Я думаю, что нет, потому что можем провести аналогию с нашей компанией, с тем, чем мы сейчас в Scalarr занимаемся. Мы натренировали модель, мы видим этот уровень fraud-а. Но наши эти плохие парни, которые подделывают трафик, они все время меняют алгоритмы. То же самое происходит с этим invest-банком. Они натренировали систему, она начала видеть, а потом что-то произошло в мире, что изменило правила оценки. Больше уже не важны те правила, которые были, и надо перетренировывать сети. То есть я бы не сказал, что АІ полностью заменит людей. То есть человек делает много рутинной работы. Чтобы проанализировать компанию, надо прочитать 20 страниц а4. А искусственный интеллект ищет ключевую информацию, и из 20 страниц делает одну. И, читая одну страницу, человек узнает, надо инвестировать или нет. То есть он делает final decision. Может, позже мы дойдем до того, что эти алгоритмы станут настолько продвинутыми, что мы сможем заменить полностью человека. Но это еще не сейчас.
АІ активно используют во всем мире в качестве вычислительно-обрабатывающего мозга, а как с его воплощением в реальном теле в виде роботов
49:07 И на финал как раз. Ты, когда слышишь "искусственный интеллект", "deep learning", "машинное обучение", то представляешь себе, мягко говоря, терминатора какого-то, что мы идем куда-то к искусственному интеллекту. На самом деле здесь сразу мы переключаемся на идентификацию паразитов на рыбах, или груш, или апельсинов на деревьях. И как-то не вяжется. То есть мы все-таки движемся туда, или это все-таки разные вещи?
Я очень рад, что вы спросили. Именно сегодня, в день записи этого интервью, компания Boston Dynamics запустила в массовую продажу первых роботов, этих собачек, - я не помню, как они называются - автономных роботов, которые будут жить с человеком. Это первый пример, когда это масс продакшн, его уже можно купить для дома. То есть задача какая? Она может что-то носить, навигуватися по квартире, открывать двери и т.д. Вы понимаете, что первый раз в истории человечества запустили работа в нашу жизнь? То есть это не робот-пылесос, который ездит, а на ногах, как собака, ходит.
Просто мы видим, понимаете, мы видим много примеров применения: там рыбы, паразиты, prediction компании, детекция fraud-а, финансовые злоупотребления - это одна ниша. А вторая - это Роботикс - это очень мощная ниша. Уже все производства компаний машины собирают на роботизированных линиях. Теперь роботы будут помогать в нашей повседневной жизни. Есть уже экзоскелеты, которые появились и помогают человеку легче ходить, снимать нагрузку и т.д. Просто об этом не так широко публикуют, чтобы не пугать. Но робот, который прыгает, делает сальто и ходит, и может распознавать объекты, носить коробки, уже есть.
Когда человек начнет сливаться с техникой, вживляя себе чипы и превращаясь в биомеханизм, какую мощь он получит. И что будет с несогласными
50:59 Для человечества не получится ли так, что мы станем не самой верхушкой цивилизации и развития?
Я бы так сказал: смотрите, что делает Маск. Он запустил компанию, Facebook выкупает стартап, который управляет компьютером с помощью мозга, Маск основал еще один стартап Neuralink, который объединяет компьютер и мозг. То есть мы что видим? Что человек хочет усиливать свой мозг с помощью алгоритма. Почему? Потому что, когда тебе задают вопрос, что произошло в 1573 году на берегу какой-то реки, твой мозг не может запомнить все факты, а сеть может. Если у тебя есть ссылка к сети, ты можешь отвечать на любой вопрос, ты можешь анализировать очень многие факты. Но как это будет происходить, мы узнаем лет через 20, когда это встроится. То есть человек будет бионическим. Кто захочет, может встраивать себе чип для авторизации - это просто удобно. Кто-то может встраивать чип в голову, который будет тебя просто конектиты к сети без смартфона. Это тоже будет удобно. Может, через 20 лет так все будут делать. Алгоритмы будут все больше и больше развиваться, становиться умными, мы будем улучшать качество, точность и т.д.
Но будут и люди, которые будут говорить "Нет". Они будут "староверы", как говорится. Они будут ехать в лес и говорить: "Я здесь живу по старым правилам", как это, знаете, в футуристических фильмах показывают. Это все будет, мне кажется. Просто не надо этого всего пугаться, как мобильных телефонов, веб-сайтов. Это все придет.
Ок. Спасибо, Борис, за интересное интервью.
Хотите быть в курсе новостей? Смотрите наши видео на канале Perceptron >>>
Наши контакты >>>

- Контент-маркетолог TQM systems Nataliya Raevskaya
- 6/12/2020 10:20:55 PM
-
Интервью


