Штучний інтелект для бізнесу - практика застосувань
Те, що штучний інтелект вже реально існує і навіть створюється в Україні, вже не секрет. Про це нам розповів у інтерв’ю Олесь Петрів. І може нам із нашими темпами впровадження навіть звичайного електронного документообігу здається не на часі дивитися на такі інновації. Але технології рухаються, і смартфони сьогодні у кишені кожного, а з ними нам доступні усі принади комп’ютерного світу. І ми самі стаємо дедалі доступнішою аудиторією для бізнесів, що роблять ставку на машинний інтелект. Спостерігати, споживати чи придивлятися та імплементувати у свою роботу?
Наш гість Борис Працюк розповість про практичний досвід продажу і використання AI технологій:
- як вже зараз вибудовується бізнес навколо AI, чому американські компанії розвивають свої стартапи в Україні;
- яка робота штучного інтелекту затребувана, від підрахунку апельсинів, дизайну меблів та розпізнавання положень тіла працівників до інвестиційних проєктів та автопілотування;
- де є безкоштовні бібліотеки для навчання нейромережі, і чому потрібне ліцензування;
- скільки коштує проєкт, фахівець з AI, оренда серверу;
- тема e-commerce та магазини майбутнього: у що вкладають мільярди Amazon, eBay та Alibaba;
- де не варто довірятися неживій істоті;
- та коли і для чого люди самі забажають стати кіборгами, як це відбуватиметься, та що буде з незгодними.
І ще багато цікавого в нашому відео розповість Борис Працюк, CTO в американському стартапі Scalarr, в минулому Head of R&D (керівник відділу досліджень і розробок) в Ciklum. Спеціаліст із розробки систем машинного навчання із досвідом роботи в Сеулі (Південна Корея) у дослідницькому центрі.
Відео: Нейромережі, штучний інтелект, машинне навчання в українському бізнесі
Зміст інтерв'ю
- 0:35 Кар'єрний шлях фахівця з AI: КПІ, корейські розробки, Ciklum і посада СТО в американському стартапі
- 3:04 Просте пояснення технології штучного інтелекту
- 4:43 Бізнес застосування технології розпізнання візуальних об'єктів
- 6:52 Язики для роботи з нейромережею і технічні особливості технології
- 8:39 У чому полягає лідерство і його математична формула
- 10:08 Дані, які українська влада планує надавати бізнесу і найбільш затребувана інформація в світі
- 11:47 Інформація, яка закрита державою. Відповідальність за використання даних (на прикладі medical data)
- 13:03 Чим викликаний такий активний розвиток AI технологій. Чому AI технології так слабо представлені в сфері медицини
- 15:26 Сервер під капотом Tesla і необхідні розробки для демократизації цього товару. Про автомобільний ринок в перспективі 5 років
- 16:36 Українські бізнес-розробки Scalarr на конференціях CVPR и NIPS. Для чого створюються інновації і яка роль бізнесу в цій сфері
- 18:51 Transfer Learning - адаптація нейромережі для задач в інших областях, розподіл робіт з первинного створення мережі і адаптивне перевивчення
- 21:08 Готові бібліотеки для нейромереж і ліцензування даних
- 23:50 Про Hadoop і sql - що, де і навіщо застосовується
- 26:30 Еволюція обов'язків програміста. Необхідні навички для успішної роботи
- 27:31 Які переваги від використання штучного інтелекту в бізнесі
- 28:18 Методологія роботи за проектами AI і навіщо застосовується класичний waterfall
- 29:31 Хто в Україні купує нейромережі і як це можна порівняти з іноземним клієнтським портфелем
- 30:14 Скільки коштують проекти за AI, ціна оренди потужностей, покупки серверів. Що впливає на ціну, і причому тут біткоіни
- 31:44 Ціна фахівців з AI у нас і в Лондоні і їх наявність, формування вартості проекту
- 33:06 Чому бізнес ще погано розуміє навіщо йому Computer Vision, і за рахунок чого розвивається ринок АІ на прикладах
- 34:03 За рахунок яких елементарних удосконалень бездоганну конкурентну перевагу в майбутньому для бізнесу можна створювати вже зараз
- 35:56 Прогноз зміни в e-commerce. У яких магазинах мріють купувати речі зайняті чоловіки, і як вже продають в Америці
- 38:31 Як буде розвиватися людина, коли нейромережі почнуть їй рекомендувати що робити, наскільки їм можна довіряти і залежати від них
- 40:19 Приклади сфер, де AI може зіграти злий жарт з людьми
- 42:15 Хто відповідальний за розвиток технологій людства, інженери або політики
- 43:07 video-detecting по людям - популярна іграшка, як вона може бути застосовна для бізнесу
- 44:45 Для чого знадобилося ідентифікували пози людини на відео для великого автомотива. Розпізнавання положень тіла може рятувати життя
- 47:03 Інвестиційний банк задіяв штучний інтелект у визначенні інвестиційної привабливості, і чи потрібні їм тепер експерти-люди
- 49:07 АІ активно використовують у всьому світі в якості обчислювально-обробного мозку, а як з його втіленням в реальному тілі у вигляді роботів
- 50:59 Коли людина почне зливатися з технікою, вживляючи собі чіпи і перетворюючись в біомеханизм, яку міць він отримає. І що буде з незгодними
Весь текст інтерв'ю
Всім привіт! З вами Зосим Максим на каналі "Perceptron", і сьогодні ми в гостях у Бориса Працюка. Ми зараз в UNIT.City. Погнали!
Кар'єрний шлях фахівця з AI: КПІ, корейські розробки, Ciklum і посада СТО в американському стартапі
0:35
Привіт!
Давай для наших слухачів, для людей, які нас дивляться, ти трохи розповіси про себе, свій життєвий шлях, як ти до цього дійшов, до такого життя?
Як я дійшов на цей коридор, да? Якщо довго казати, то все почалося з математичного ліцею, я 15 років пронавчався і пропрацював у КПІ. Я навчався в ліцеї, потім пішов - 6 років - у КПІ, 5 років працював на кафедрі, писав там дисертацію. І паралельно працював. З 2004 року я почав працювати сішником, як тоді казали. Потім на п'ятому курсі мені запропонували поїхати у Корею, щоб поробити дослідження в Ренділабі. Так що я був біля Сеулу, пропрацював там десь 5 років. І там, і віддалено, потім пішов в аспірантуру, закінчив. А вже коли закінчив, вирішив більше не виїжджати, тому що пропонували поїхати в Корею, продовжити там працювати.
1:35 Що ти там робив безпосередньо?
Я там робив все, я займався embedding, я там робив у IUT, але воно ще не називалося IUT. Різні сенсори робив, різні прилади. В принципі, займався навчанням молоді, колег своїх і т. д.
Вже коли повернувся, я працював в “Андроїді”, був Mobile-розробником. І коли закінчив, дописав свою дисертацію, захистився, вирішив нікуди не їхати і спробувати знайти себе тут. Змінив компанію і пішов у компанію свою попередню Ciklum, де я сім років відпрацював. А після Ciklum, нещодавно, 2 місяці тому назад, я пішов у компанію Scalarr - це американский стартап. Я тепер CTO, і ми рухаємося разом із біг-дата і штучним інтелектом до світового визнання.
2:24
Які з проєктів із штучного інтелекту ти робив? Тобто як ти потрапив саме в цей напрям?
Якщо подумати про компанію Ciklum, то останні 4 роки я був Head of R&D, і ми там робили дуже багато: ми робили computer vision, ми робили big data, в плані аналіз табличних даних. Робили усілякі R&D проєкти, де ми змішували аналіз звуку, алекси, google home, conversational commerce, коли ти розмовляєш, робили концепти змішані IUT + conversational commerce. Коротше, дуже багато проєктів. Так щоб швиденько сказати, які ми можемо робити, то треба сісти і розповідати про кожен.
Просте пояснення технології штучного інтелекту
3:04 А якби тебе запитали: “Поясни школяреві, що таке штучний інтелект і ML, що б ти йому розповів?”
Це дуже легко. От якщо взяти… це дошка наша. Я завжди малюю отак лінію, й кажу: “Оце наш графік, і оце наші точки. Наприклад, це покупці, які щось в нас будуть купувати, а ось ці не будуть. І нам треба провести лінію. Кожен школяр може взяти лінійку і провести лінію ось так. Розділити на 2 групи: куплять - не куплять. І тепер треба написати програму, яка проведе лінію за тебе, і буде вміти проводити. Тут дані можуть мішатися, виділятися в різні групи, кластери. Програма штучний інтелект повинна проводити цю лінію, розділяти на групи і робити аналіз. І це, в принципі, в двох словах про машинне навчання. Ми так само аналізуємо трафік і розділяємо його на гарний трафік і поганий.
3:57 Це і даних стосується, і зображень, і всього? Завдання математично однаково звучить?
В принципі, ми навчаємо систему бачити якісь патерни. Якщо це розділення двох груп, це проведення простої лінії. Якщо це зображення, то ми вчимося розпізнавати всякі edges, градієнти в зображеннях, бачити очі. Якщо це звук, то ми навчаємо нейронну мережу бачити патерни в спектрі, або ще в чомусь. Тобто це завжди вивчення даних. Ми беремо дані і навчаємо на цьому нейронну мережу, ми балансуємо ці коефіцієнти і мінімізуємо функцію. У нас сходиться, сходиться, сходиться, і коли вона зійшлася, ми можемо потім додиктувати певні патерни.
Бізнес застосування технології розпізнання візуальних об'єктів
4:43
Ми всі знаємо купу всіляких завдань, навіщо це потрібно: визначення особи для соцмережі та інше. А для чого це потрібно бізнесу?
Ви бачили - на вході в UNIT.City стоїть автомат, і в мене є картка. І вони дивляться на моє лице. І кожен ранок, коли я проходжу - авторизуюся. Я кажу, що я тут працюю, я Борис, і ось це моє зображення. І сьогодні, коли я вас проводив по цій картці, він сказав "неавторизований відвідувач", тому що не співпадає обличчя твоє і те, що кожен день він бачить. І це бізнесу треба: це безпека, це автоматизація процесу. Ти в’їжджаєш на парковку, і не треба буде мати якогось контролера, який впізнає драйвера, впізнає його машину, скаже "Добрий вечір". Інтелект це зробить за нього. По суті, автоматизація - це пришвидшення процесів. Якщо це виробництво м'яса, то зараз всі знаємо, хто нарізає це м'ясо - це людина стоїть. Навчити машину різати, як людина, тушу - легко. І вона буде вже розділувати цю тушу без участі людини. А людина може читати книжки, навчатися, мріяти про щось велике.
5:54
Розкажи, на технічному рівні - що це? Тобто як це відбувається?
На технічному рівні ми беремо великий датасет, ми беремо багато даних. Якщо у нас є обличчя, воно має певні патерни, є очі, є ніс, є рот. І коли ми завантажуємо ці багато-багато зображень, по суті, ми вивчаємо, як виглядає обличчя. Тобто ми бачимо, що є певні овальні ніші для ока, є ніс. І коли ми пропускаємо через нейронну мережу оці зображення, по суті, це зображення розкладається в такий великий ряд цих вхідних інпутів, і ми запускаємо. І нейтронна мережа запам'ятовує, що якщо ми детектимо обличчя, то це має такий приблизно pattern, це таке співвідношення пікселів. Наприклад: якщо ми бачимо собачку, або кішечку, або людину, ми вже знаємо, що якщо там вуса такі довгі, то це паттерн кішки, і нейронна мережа зразу побачить це.
Язики для роботи з нейромережею і технічні особливості технології
6:52 Ти вже розповідаєш архітектурно на рівні квадратиків. А в загальному, технічно, що таке нейромережа? Ось я сиджу, я школяр, і мені хочеться почати колупатися. Я хочу зробити першу якусь нейромережу свою.
Технічно це просто набір різних бібліотек, які дозволяють організувати... це вже бібліотеки з певним набором алгоритмів, які уже створили, і ти береш просто конфігуруєш оту архітектуру, про яку я розповідав, і починаєш навчати, навчати... Як? У тебе є дані на диску, і ти описуєш, як, в яких форматах ці дані подавати на вхід нейронній мережі, як контролювати навчання.
Це, по суті, така бібліотека, з уже існуючими інструментами, яка дозволяє швидко почати навчати нейронну мережу.
І треба знати Python. Якщо ти Python не знаєш…
А інші мови не підходять?
Щоб я зараз не обманював, є інші мови, можна це робити. Є такий фреймворк Scala, але 90% - це Python. Можна щось у Матлабі робити. MatLab - це одна із перших систем, яка була створена для науковців, і вона створена науковцями для науковців. Там своя мова, але вони зараз теж багато роблять для... але 90% світу - це Open Source бібліотеки, які дозволяють навчати нейронну мережу. Вже можна вдома сісти і почати навчати нейронну мережу.
У чому полягає лідерство і його математична формула
8:39 Розкажи, ця формула математична лідерства звідки взялася?
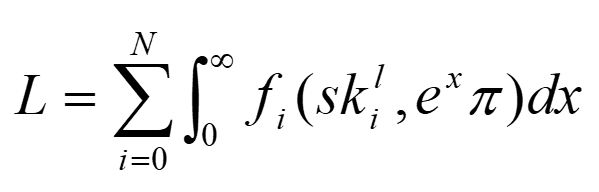
Знаєте, я дуже люблю математику, і я команду свою запитав: “Хто я такий? Навіщо я вам потрібен взагалі? Project Manager потрібен, щоб менеджити, QA - щоб тестувати, девелопер - щоб писать код, науковці - щоб знаходити гіпотези. Нащо вам Head або лідер?” Я так засумував трошки. Кажу: “Може, я з вами буду писать код?” Вони кажуть: “Дивись, ти нам потрібен, тому що без тебе якось воно не йде”. Я тоді замислився, а в чому ж є суть лідера? Чому раніше люди йшли у бій за командиром, і взагалі, як це працює? Почав аналізувати, і зрозумів, що лідер - це дуже проста людина. Людина, яка поєднує сильні сторони своєї команди, робить з команди такий squad (загін), який пробиває нові стіни. Тобто з гарною командою.
Математичний сенс є?
Математичний, якщо перейти від того, що лідер збирає команду і пробиває стіни з цією командою, то ось тут сума: це Н - кількість людей - сума людей, які мають в собі якусь функцію, яка залежить від skills і experience, - це його навички і досвід життєвий. Враховуючи, що X у нас змінна по dX, то ми від нуля до нескінченності, бо ми живемо, і це час, і ми весь час накопичуєм досвід і навички. Тобто лідер - це людина, яка об'єднує людей з різними скілами і досвідом.
Круто! Це ти сам? Не підглянуто?
Ні, ні! І ще тут є такі баталії, чи правильна вона, але...
Дані, які українська влада планує надавати бізнесу і найбільш затребувана інформація в світі
10:08
Ми говорили з приводу навчання на датасетах. В твоєму виступі на i-Forum 2019 ти показував слайд, там є прямо назва, якщо я правильно пам'ятаю, “COCO і Mapillary”, тобто все це назви датасетів безпосередньо?
“COCO - це такий датасет, який можна використовувати для тренування ваших нейронних мереж. Що завдяки йому можна робити? Можна робити object detection, але вже object detection відбувається не рамочкою, а ми наче робимо як сегментацію. Ми багато чого можемо робити. І що це нам каже? Нові технології вбивають старий підхід".
Це окремі прямо зараз ніша і ринок, який утворився в результаті нейромереж?
Дивіться, зараз така трансформація в світі, що всі б'ються за дані. Ось був на минулому тижні Open data forum, наша українська нова влада, з правилами, люди, які це хочуть просувати, вони кажуть: "Ми хочемо зрозуміти, як дати дані бізнесу, щоб вони робили більше бізнесу". Тому що у всьому світі є медичні дані відкриті або закриті, є телекомунікаційні, різні типи даних, і держава їх надає, або бізнеси їх продають. І ми виходимо на рівень, коли, маючи правильний датасет, маючи правильних датасетистів, ми можемо змішати і отримати просто бізнес на пустому місці. От тому є ринок даних, і це вже давно в світі він є, де продають датасети.
Інформація, яка закрита державою. Відповідальність за використання даних (на прикладі medical data)
11:47 Наскільки я знаю, на сьогоднішній день вже є більше 140 відкритих реєстрів, якими можна користуватися, або вони щось нове хочуть вносити?
Вони хочуть більше додавати і питати в бізнеса, які датасети треба дати, що ще можна додати, чого не вистачає? Зробити лібералізацію. Щоб це було відкрито, чисто, зрозуміло. Якщо я взяв ці датасети, яку я відповідальність несу? Тому що якщо це medical data, то як я їх буду використовувати?
Medical як раз, здається, не відкриті зараз.
Взагалі немає цього. А в Medical - це топ 1 в світі, по Medical-data, по аналізу MRA-знімків цих рентгенівських, по знаходженню пухлин і т.д. І наші спеціалісти в Україні - одні з найкращих у світі, вони роблять гарні публікації, але датасети вони беруть світові.
Там вони відкриті?
Там є певні університети, які для research відкривають маленьку частинку. Ви розумієте, якщо нам дали 1%, і наша нейронна мережа показує 99-95%, то якщо нам би дали увесь датасет, то ми б отримали 99,99999...%, і це було б безпомилково. Це точність.
Чим викликаний такий активний розвиток AI технологій. Чому AI технології так слабо представлені в сфері медицини
13:03 Наскільки я знаю, відсоток визначення за допомогою людини, коли вона дивиться, набагато нижчий. Чому людство досі в промислових масштабах не використовує це?
Давайте повернемося до історії:
"В 12 році що відбулося? Був такий ImageNet Challenge, коли люди намагалися... писали алгоритми для розпізнавання картинок. Це виглядало таким чином: от, наприклад, container ship, - ви бачите, там така баржа з контейнерами, - вони намагалися вгадати, що знаходиться на зображенні. І от в 12 році AlexNet, здається... Хто пам'ятає історію? Вони зробили на нейронних мережах рішення, яке за якістю розпізнавання було, здається, на 10% чи там на 7 краще, ніж усі попередні методи. І якість розпізнавання кожен рік, тобто error rate, падає, і якість підвищується. Тобто зараз це 98% чи 99 точність. Чому так? Тому що з'явилися GPU".
Почали займатися deep learning, потрібні стали GPU. Компанія NVIDIA швиденько переформатувала ігрові GPU у deep learning, почали давати потужність. Більше потужності - швидше ітерації, воно почало прискорюватися. За 7 років зараз у нас вже їздить Tesla, яка сама їздить. Це за 7 років. Research (дослідження) йшли 25 років, але ось такий експоненційний прорив пішов завдяки...
14:41 Чому так? Ти на тому ж форумі показуєш слайд, це ж не новий хайп, не нова технологія?
Вона вже була, не було датасетів. Знаєте, скільки відео із фотографіями зараз люди завантажують у Google і у Фейсбук? Мільярди! І це датасети. І тому ці датасети пропускаються через кластери GPU, і ми отримуємо нові нейронні мережі, нові статті, нові бібліотеки, які дозволяють тренувати. Прийшов час, я б сказав. Тому що технологія пришвидшення цього навчання GPU дозволила перейти і навчати не 9 годин нейронну мережу, а 5 хвилин. Ти робиш не одну добу інтеграцію, а за день 25. І воно почало пришвидшуватися. Просто настав час.
Сервер під капотом Tesla і необхідні розробки для демократизації цього товару. Про автомобільний ринок в перспективі 5 років
15:26
Ти кажеш з приводу розпізнавання для Tesla, що зараз все одно сервер, який стоїть в машині.
Поки що так.
І в тому числі в Tesla стоїть сервер.
Якщо отак підійти до стенду там, на конференціях, де вони показують NIPS. Вони кажуть, що дійсно зараз поки що відкривають капот, і там стоїть великий потужний сервер, з великими відеокартами, які споживають багато енергії - це концепт. Кожна компанія: Тесла, NVIDIA працює над отаким чіпом, який буде дозволяти з малими енергозатратами опрацьовувати цей image puzzle. Обличчя детектити - це вже легко, це було складно 10 років тому назад. Там був такий от (величезний) сервер, тепер можна робити на телефоні Face-ID. Тобто вони все оптимізували. І тепер наступний крок ще п'ять років - і це буде Production Rate, і всі машини будуть мати систему моніторингу зіткнень, наближення, автоматичної зупинки, якщо вона бачить. Дуже вночі допомагає, тому що ти не бачиш, а камера бачить, і можна дуже багато зберегти життів.
Українські бізнес-розробки Scalarr на конференціях CVPR и NIPS. Для чого створюються інновації і яка роль бізнесу в цій сфері
16:36
Ти згадуєш 2 конференції наймасштабніші, це CVPR (щорічна конференція з комп'ютерного зору и розпізнавання образів) і NIPS (конференція з машинного навчання та особливостей нейробіології, яка проводиться кожного грудня). Ти був на обох, як я зрозумів. Розкажи, про що і як взагалі.
Я як гарний лідер не їздив туди, тому що поїхати туди дуже дорого, я свою команду туди відправляв. Вони були декілька разів і на CVPR, і на NIPS. Навіть в цьому році на CVPR команда робила презентацію, воркшоп. Вони зробили цікавий paper… Це рівень. Ви розумієте, що в Україні вже робляться такі дослідження, що стосовно будь-якого об'єкта вони робили prediction (передбачення): який там скелет. Для будь-якого об'єкта вони малювали структурні грані, де в нього скелет, на чому все тримається. Це, по суті, центр мас. Це дуже прикольно.
Не тільки для людини?
Для будь-якого об'єкта, для яблука, для стола. Тобто вони можуть намалювати, що в ньому є несуче, центр. Це цікавий research, і вони просто проводили воркшоп і пояснювали, як вони це робили, і у них була година на представлення.
Для чого? В бізнес-задачах як це можна використовувати?
А дивіться. Тут дуже цікаво. Будь-яка людина, яка займається АІ, вона займається заради АІ - їй подобається ця штука, а уже задача бізнесу, - це моя була задача, - зрозуміти, як оці paper-и, всі свої наукові досягнення перенести на бізнес.
Ми робили проєкт: ми детектили апельсини - автоматичний підрахунок апельсинів на дереві. Людина ніколи не підрахує дуже точно всі апельсини. Одне дерево, друге, а там їх мільйони - 1,6 акрів.
"Приходимо до клієнта і кажемо: “Боже, 83 % - це ж так погано!” Він каже: “Пацани, це круто! Це ж 83! 75 - у людини, а у вас 83, так що ви молодці".
Це тільки штучний інтелект, тільки камери. І якщо не буде цих research-ів, які просто дозволяють якісно детектити скелет, форму і т.д., то не буде цих лего-кубиків, з яких збирається бізнес-рішення. І науковці роблять отакі дослідження, paper заради paper, а потім приходить бізнес-компанія, яка має свій департамент, і робить з цього value.
Transfer Learning - адаптація нейромережі для задач в інших областях, розподіл робіт з первинного створення мережі і адаптивне перевивчення
18:51 Ти говорив ще про одну технологію - transfer learning, коли у нас є навчена нейромережа, приміром, розпізнавати чи апельсини, чи яблука. У нас апельсинів немає, тому застосуємо це до груш.
У мене відразу виникло питання: сама технологія і підхід - він застосовується. Яблуко, груша, апельсин між собою схожі, а якщо ми говоримо про детектинг: ось у нас є нейромережа, яка яблука розпізнає. Це взагалі може бути застосовано до човнів?
Підхід дуже прикольний чим? Що ми тренуємо нейромережу, потім ми зберігаємо її конфігурацію, ці всі коефіцієнти, для того щоб ми її, наприклад, натренували детектити стіл і пуф, на чому ми сидимо. Вони були певної форми, певних моделей. Ми змайстрували пуф, і людина може сидіти, а ми хочемо перейти на стільці. І ми беремо просто оцю модель, яка вже навчилася. Що значить модель? Вона навчилася бачити ці грані, вона навчилася бачити форми, що воно там м'яке. І ми беремо і перенавчаємо, тобто оцю титанічну роботу, яка була якимись інженерами проведена, ми її трошки донавчаємо, трошки коригуємо. Це як навчити бачити машини, і ця модель буде бачити машини: колеса, дах. А потім нам треба бачити, наприклад, тільки одну модель. І ми беремо оцю от базову нейронну мережу, яка дуже гарно розпізнає машини, автобуси і т.д., і донавчаємо на specific business issue, на специфіку зон.
Цей підхід Transfer Learning працює взагалі круто для бізнеса, але чи зможемо ми, якщо ми натренувалися на апельсинах, бачити машину? Мабуть, ні. Тому що дуже багато там треба буде перенавчати, і коли ми перенавчимо, то від тої початкової нейромережі нічого вже не залишиться, вона вся перенавчиться.
Transfer Learning гарно підходить, коли у вас є схожі задачі. Інститут науковий research зробив 90% важкої роботи, віддав це бізнесу, а далі я бачив дуже круту роботу в дизайнерів: нейронні мережі, які розпізнають меблі. Все, що вони зробили, - вони додали туди дещо і почали розфарбовувати ці меблі. Вони це дуже швидко зробили: базова модель була, і вони донавчили її своїми роботами, і воно почало розфарбувати стіни, вішати картини, і це вже не рік роботи, а місяць.
Готові бібліотеки для нейромереж і ліцензування даних
21:08 З приводу "інститут зробив research", ти згадував 26 різних. Здається, це Стенфорд. Як вони це надають? Це просто Open Source бібліотека, якою користується, хто хоче?
Так, там є ліцензія, в усьому світі дуже важлива ліцензія. Тому що, якщо, наприклад, ви побудували бізнес, ніхто цього не побачив, ви почали зростати, і прибутки теж. І коли у вас буде декілька мільйонів, на вас просто подадуть до суду, і ці гроші підуть в Стенфорд, тому що ви порушили базову ліцензію. Як дізнатися? Дуже легко. В Європі і в Америці є спеціальні інститути, які роблять аудит вашого рішення, і ви повинні надати цю інформацію. Тобто якщо ти починаєш робити щось з АІ, краще дуже сильно поважати ліцензії. Тому для research, для того, щоб подивитися, чи працює цей концепт, підходить, коли починаєте робити бізнес-рішення, треба самому зібрати свій датасет і перенавчити нейронну мережу на своєму датасеті. Тому що тільки так він буде legal рішення.
А те, що надає Стенфорд, це не для комерційних проєктів?
Там треба читати. Те, що для навчання, для наукових цілей - 100%. Там завжди маленьким шрифтом написано "for personal use only". Тому що вони для того, щоб навчати студентів, нове покоління працювати з АІ, дуже круто, а ось для commercial use, коли ти вже хочеш на цьому заробити, тут вже питаннячко, скільки ж effort-ів було інвестовано в цю систему. І треба платити. Я це не дивився, чесно.
22:53 Ти у виступі розповідав про замовника з інвойсами, про process automation. З яким завданням він взагалі прийшов?
В принципі, він прийшов з іншою задачею. Це був в нас такий воркшоп. В нього задача була зробити наступний модуль системи, він давно вже працював з нами, і треба було йому зробити якийсь там модуль. А потім він каже: “О, а я ще хочу там аналітику. Можна мені зробити там email?” А я кажу: “Які в вас там параметри, як ви трекаєте?” Він каже: “В мене один параметр, в email: відкрито / не відкрито. Можна мені зробити data science?” А я кажу, мало параметрів, мало даних, немає датасету. Тобто треба трекати, коли він відкрився, коли закрився, чи відкривав він ще раз, скільки разів він повертався до цього документа. Ну, тобто для того, щоб побудувати, замінити людину на персоналізований алгоритм, нам треба мати поведінку людини. А от поведінку трекати можна саме цими івентами, подіями.
Про Hadoop і sql - що, де і навіщо застосовується
23:50 Через якийсь час він до вас повернувся з датасетом?
А він нікуди не пішов. Ми йому дали рекомендації, він пішов збирати цей датасет. Ми кажемо, півроку нам десь вистачить, щоб почати робити ті усі продукти по view concept. Кажу, іди збирай, потім повертайся, і ми будемо тобі робити.
І повернувся він з SQL. Розкажи, будь ласка, для тих, хто не розуміє, в чому різниця. Ти згадав там Hadoop і SQL. В 2 словах, в чому різниця, що це і навіщо?
В принципі, це непогано. SQL (structured query language) - це така спеціальна мова, яку ти можеш писати і з бази даних виймати свої дані.
Як раз про SQL, напевно, знає більшість людей, а ось про Hadoop - половина не знає.
(Hadoop - проєкт фонду Apart software foundation. Вільно розповсюджуваний набір утиліт, бібліотек і фреймворків для розробки і виконання розподілених програм, що працюють на кластерах із сотень і тисяч вузлів).
Чому зараз трошки все помінялося? Якщо раніше нам вистачало однієї бази даних, то коли наших даних стає мільйон, постає вже ідея перебудови індекса. Це догма. Для мільйона нормально. А мільярд? А 10 мільярдів? А якщо 10 мільярдів за годину даних? Ми вже не можемо застосовувати старі підходи, тому виникає Hadoop - це така екосистема паралельних обчислень. Ми можемо робити ноди - це окремий сервер - і легко масштабувати систему, вона вся розподілена. Тобто там є HDFS - файлова система. Тому що ми не завжди отримуємо дані як запис в базі даних. Інколи нам приходять invoices - це фізичні pdf, excel, і їх треба десь складати. Уявимо собі глобальну компанію, яка є в Америці, в Україні, в Японії. Ми отримали invoice в Японії, а процесінг відбувається, наприклад, в Америці. Нам треба синхронізувати усі ці три сховища, і це все робиться автоматично.
Є така HDFS-система (hadoop distributed file system) - вона розподілена, тобто ти поклав, вона автоматично на всі ноди зробила копію. Тобто ти працюєш з файлом, але де фізично він знаходиться, ти не знаєш. І раніше було як? Чому це важливо? Тому що міняються підходи до програмування. Раніше ти міг собі на комп'ютері підняти базу, на своєму лептопі, локально це протестувати, потім протестувати з прод-базою, вилити і т.д. Зараз це змінилося. Враховуючи цю hadoop децентралізовану систему, все стало "decentralized". Все приходить в Docker, в Kubernetes. Docker - це контейнер, в який загортається софт, Kubernetes - це софтвер, який менеджить ці всі контейнери. І, уявіть собі, це можуть бути тисячі цих контейнерів, вони піднімаються, схлопуються, дані літають, тому DevOps нам дуже сильно допомагає в цьому.
Еволюція обов'язків програміста. Необхідні навички для успішної роботи
26:30 Для програміста, який це робить, що змінилося?
Просто різні tools з'явилися. Він починає працювати з Hadoop, він пише spark job-и. Spark - це такий framework, який там є, і можна писати на Java, Scala, Python. І ти пишеш. Раніше ти писав SQL запит, а тепер ти пишеш spark job. Це алгоритм, як ти хочеш витягати дані, і ти можеш написати процесінг - беремо файл, парсимо його, складаємо у якусь базу. Беремо Twitter-коментарі, парсимо, складаємо в базу. Наприклад, якщо беремо якийсь файл, і не вистачає даних, шукаємо, де і як заповнити ці дані. Наприклад, Борис Працюк, в мене пропущений телефон. А у нас є 10 source-баз, де можна пошукати Бориса Працюка, і знайти там. Тобто робимо, мініфікуємо датасети, щоб було уже все заповнене, щоб можна було тренувати нейронну мережу.
Так що змінилися інструменти - дуже багато їх з'явилося.
Які переваги від використання штучного інтелекту в бізнесі
27:31 В результаті, який process automation у цього клієнта вийшов? Який результат цього проєкту?
Сказати так відверто не можу, там же багато під NDA (non-disclosure agreement – угода про нерозголошення інформації). Знаєте, коли питають, розкажи нам результати будь-якого АІ проєкту, ти зразу думаєш, а чи не розповім я якісь властивості алгоритму чи щось таке, що потім прийдуть мені і скажуть: NDA...
В двух словах: у нього вийшло. Я не знаю, до речі, цифру фінальну, на скільки там що скоротилося. Є в інших проєктах, там які є бенефіти, на скільки, на 30% відсотків скорочувались затрати на кол-центр. Наприклад, у клієнта, ми йому чатбот робили, і він впровадив, і в нього зменшився load кол-центра - це до мільйона баксів на рік.
Методологія роботи за проектами AI і навіщо застосовується класичний waterfall
28:18 Ти розповідав, що ви робите DL is a service (Deep Learning is a service), але при цьому на наступному ж слайді, як виглядає структура вашого проєкту, то я для себе побачив такий класичний waterfall в якійсь стадії. Поясни, що це таке?
Сервіс ми робимо для клієнта, а як він виглядає всередині - це ті стадії, які ми робимо, коли ми приходимо до клієнта. Але для клієнта - йому взагалі неважливо це знати. Він завжди питає: "А що під капотом? А як ви це будете робити?". Ніхто не купує так: зроби мені deep learning, зроби мені АІ, і от- на тобі! - мільйон. Ні, всі питають: як ви будете робити, а як це інтегрується з нашим бізнес-процесом? Дуже багато питань. Тому, виходить, для клієнта у нас було декілька кейсів гарних. Прийшов клієнт і сказав: "В мене є бізнес проблема", дав дані і пішов. А через два місяці ми дали йому нейромережу, яка вирішує його бізнес питання. І ми йому не показували нічого: ні ці графіки, нічого. Він купив as-is. Це був дуже прикольний кейс. Інший клієнт, дуже багато клієнтів, до речі, питають: "А як це будете робити? А як у вас security?" Тому був такий графік waterfall.
Хто в Україні купує нейромережі і як це можна порівняти з іноземним клієнтським портфелем
29:31 Якщо ми говоримо про клієнтську базу, то зараз це більше європейський замовник, чи українські замовники вже теж починають йти до цих даних?
У нас був досвід з українськими клієнтами. Було 23 presale, це був агросектор, ми хотіли зробити агро-campaign. Всі ж кажуть "агро в Україні на хайпі". Ми проговорили з 23-ма клієнтами з України, це великі холдинги, маленькі холдинги.
Один ми провтикали, ми не встигли deadline, ми не встигли подати нашу estimation (оцінку), тому що ми його вчасно не отримали, бо вони забули нам написати, і ми не встигли. Там був би проєкт, це я знаю.
А оці 22, які ми програли, - це коли ми доходили до pricing, тому що 25 баксів коштує година серверу в cloud-і, щоб тренувати. Тренувати треба 24/7 місяць-два. Ви можете порахувати, скільки це коштує. Я навіть не казав, скільки коштує наша робота, наші знання, про те, як працювати з нейронною мережею. Я просто сказав, скільки коштує інфраструктура.
Скільки коштують проекти за AI, ціна оренди потужностей, покупки серверів. Що впливає на ціну, і причому тут біткоіни
30:14 А скільки приблизно коштує? І навіть це їх лякає?
Просто щоб піти в Амазон взяти машину або купити машину, сервер - 150 000 доларів. Нема таких грошей…
А за рахунок чого це все? За рахунок того, що там дуже відео сильне? Сервери для ERP-систем коштують набагато дешевше.
Так. Тому що коли ти тренуєш нейронну мережу, треба GPU (graphic processing unit). А GPU, коли почали майнити біткоїн, оці математичні операції дуже гарно кладуться на GPU. І викупили весь, всі викупали відеокарти. Потім почали робити більше спеціалізованих, більш дорогих, вони дуже гарно підходять, вони для майнінга погані, а для Deep Learning вони просто... Там і кеша більше, і відеопам'яті, і RAM на сервері, коротше, спеціальні сервери.
Останні сервери NVIDIA продає за 400 тисяч доларів, але вона їх не продає маленьким компаніям, вони кажуть: “Вам вони непотрібні, це треба для Uber, Tesla, які тренують оці мільярди картинок, і їм це потрібно. Вам не потрібно”. Але все одно ж таки, хайп є, і купити цей GPU-сервер - це проблема.
Ціна фахівців з AI у нас і в Лондоні і їх наявність, формування вартості проекту
31:44 Добре, а скільки може для замовника коштувати сам проєкт? Ми не говоримо про залізо. Залізо - це основні засоби, ми можемо їх купити-продати.
Такий маленький, маленький проєкт, просто показати, чи буде взагалі працювати ідея - 50 тисяч доларів.
Це нічого не робили... Щоб ви розуміли, є рівень зарплат. Ми зараз у глобальному світі девелопменту знаходимося. Україна значно дешевша з точки зору ресурсів, але програміст в Лондоні, який займається Deep Learning, коштує 300-500 тисяч доларів на рік - це його зарплата.
Це вище на півтора по ринку, виходить.
Так, тобто там середня зарплата 150-200 тисяч, а у них X2.
Чому так? Тому що їх дуже мало, їх 0,3% від всього загалу, цих девелоперів. І, я ж кажу, 7 років тільки ринок такий існує.
Чому бізнес ще погано розуміє навіщо йому Computer Vision, і за рахунок чого розвивається ринок АІ на прикладах
32:41
А є якась цифра з приводу дефіциту цих фахівців?
Я знаю, що вона є, знайти гарного Deep Learning інженера дуже складно. Гарна новина - всі зараз пішли туди навчатися, дуже багато онлайн курсів, багато хто перенавчається. І я не бачив такої статистики, по суті, не шукав, мені не дуже цікаво було. Але дефіцит є, але немає ще такого смертельного дефіциту, тому що бізнес ще не розкачався, бізнес ще не повністю зрозумів, нащо йому цей Computer Vision.
Тому що всі, хто займається Computer Vision, погано розуміють бізнес. Вони там просто роблять це, роблять, а потім - бах! - і злітає якийсь стартап. І всі питають: “Як так сталося?” А він каже: “Ну просто займався, займався…” Є такі VideoGorillas з України, вони з маленького Video Resolution роблять 4K, а зараз всі 4K мають телевізори, і старий фільм якийсь голлівудський вони роблять 4К.
Олесь нам минулого тижня розповідав.
Ось бачите, як я комплімент їм (зробив)! Оце коли Deep Learning, коли їх тренінг перетворюється в крутий бізнес. І так дуже часто буває. Ну добре, що у них там CEO розбирається, і він це правильно продає. Але дуже багато інженерів займаються Deep Learning, a бізнес не зважає на це, він ще early stage. Це ще йде адаптація. І тут хто перший встрибне, той і молодець.
За рахунок яких елементарних удосконалень бездоганну конкурентну перевагу в майбутньому для бізнесу можна створювати вже зараз
34:03 Ти думаєш, що це створить бездоганну конкурентну перевагу в майбутньому для бізнесу, який це матиме?
Я вважаю, що так, якщо ти не маєш системи RPA (robotics process automation), ти вмираєш від цієї рутини на роботі. Тобто навіть якщо ти зробиш систему Чат-бот, яка буде відповідати на питання. От уявіть: корпорація 5 000 людей, і людині треба щось знайти. Він як іде? Там є таке меню (величезне) системи 35 - 40 штук, і він іде туди і шукає. Як би ви хотіли? Ви хотіли відкрити чат: “Бот-помічник, у мене така-то проблема, я не можу заповнити якийсь там квартальний report для такого-то процесу”. Він каже: “Ось тобі link, ось тобі report - заповнюй”. Ти не витрачаєш день на пошук. Я реально знаю, про що кажу, ми можемо витратити 2-3-4-5 годин. А ще людина, яка відповідає за ці репорти, у відпустці. Прекрасно.
35:05
Так, за статистикою, 35% часу - це пошук і переструктурування інформації.
І саме це буде давати бізнесу зростання, тобто хто перший адаптується, той буде уже економити early stage. Потім - всі. Ну це наче всі перейшли на мобільні телефони.
35:18 Тобто це не тільки про поведінковий аналіз клієнтів, це навіть про внутрішні процеси.
Та про все. Дивіться, веб-сайт. Раніше веб-сайт вантажився отак (повільно) на модемі, і це було "О Боже, я маю веб-сайт"! В 2000-них всі хотіли мати свій веб сайт, зараз всі хочуть мати свій онлайн-шоп. Чи вже він є, там e-commerce. Тому що всі в мобільних, 90% дітей - в мобільному. Треба адаптувати mobile version сайтів. Розумієте, 20 років тому назад нічого цього не було. Зараз почалося, з'явився АІ.
Прогноз зміни в e-commerce. У яких магазинах мріють купувати речі зайняті чоловіки, і як вже продають в Америці
35:56 Як, на твою думку, зміниться e-commerce з впровадженням цих технологій?
Він вже змінюється. Тобто зараз, подивіться, Amazon, eBay, Alibaba - всі ці магазини інвестують мільйони, я б сказав, мільярди в системи prediction поведінки клієнта - що він буде робити, що йому запропонувати, - і це дуже класно працює. Тому що в Netflix показали, як воно працює. От ти подивився 1 фільм, і це настільки зручно! Скільки разів ти питав: “Що б мені подивитись, щоб я був задоволений?” І я поставив цю систему, подивився 1 фільм, а мені порекомендували "тобі сподобається". Після цього мені Netflix порекомендував 10, які мені сподобались, і пішла лавина. І він почав рекомендувати мені контент фільмів, яких я навіть в житті не міг подумати, що мені сподобаються, і тепер немає проблеми з тим, щоб "щось цікавеньке подивитися" для тебе, саме для тебе. Це круто, тому що e-commerce вже трансформувався, і всі ці prediction-и, вони роблять так, щоб твій контент... От я ненавиджу ходити по магазинах. Чому? Тому що одягу багато, а те, що підходить мені, - це дуже важко знайти. Я мрію просто про той e-commerce, коли я заходжу, і він, вона, воно знає, що я ношу, які я люблю стиль, речі, і т.д. Воно мені пакує, все до мене додому приїжджає, і все мені підходить, я не здаю назад. Це економить мій час, e-commerce на цьому заробляє, я їх постійний клієнт, я нікуди не йду. І вгадайте, у кого я буду купувати одяг? У тих, хто зробить цю систему.
Якщо в тебе є ця система, у тебе купують. Нема системи - ніхто вже не буде ходити по твоєму сайту, шукати опис, читати - це не треба. Навіть опис писати контент-менеджер не треба. Треба мати вигляд речі, розміри, автоматичний алгоритм підбирає людині, рекомендує. Що роблять в Америці? Їм дешевше, не питаючи, привезти більше речей, і ти потім здаш назад безкоштовно. І там 10/15 відсотків підвищення продажів, тому що як вони привезли додому речі, то ти вже думаєш: “Мені не потрібно, але віддавати назад не хочеться - залишу”. І це теж така стратегія. Так що e-commerce змінюється, і чим більше буде алгоритмів, тим буде прискорюватися і буде змінюватися.
Як буде розвиватися людина, коли нейромережі почнуть їй рекомендувати що робити, наскільки їм можна довіряти і залежати від них
38:31 Так, у нас залишилася ще пара питань. Як на мене, нам ця локація не підходить.
Так, тепер нормально.
Ось з приводу постановки різних там роликів або рекомендацій для одягу. Мене в цьому всьому питанні лякає одна річ: чи не вийде так, що ми втратимо наш культурний розвиток? Нам рекомендують те, що нам одягати, що нам дивитися. І виходить, припустимо, режисер, який зовсім по-іншому дивиться на світ. Як Netflix порекомендує тобі подивитися цей самий? Ти як і раніше будеш дивитися один і той же контент. Чи не маргіналізує це людство в своїй культурі?
Знаєте, це зараз такий є тренд в світі - називається етика нейронних мереж і машинного навчання: як і наскільки ми можемо інтерпретувати роботу цих алгоритмів. Все вкладається в цей тренд, тобто наскільки ми залежні будемо від цих алгоритмів? Я не можу дати відповідь на це питання, тому що воно дуже філософське: що буде, якщо штучний інтелект почне нам усе рекомендувати?
Давайте проведемо аналогію, що телевізор - це той самий канал впливу інформації на наш мозок, як і штучний інтелект, який нам щось рекомендує. І як поява телевізора, цих всіх теле-, медіа- штук змінила наше життя? Тобто ми почали проводити вибори по-іншому, почали впливати на свідомість людей, що їм показують, у те вони і вірять. Той самий алгоритм, якщо він буде рекомендувати там щось дивитися, людина буде... 95% не ставляться критично до інформації - вони будуть робити те, що їм скаже алгоритм. Тому, на жаль, тут будуть зловживання і погані хлопці, які будуть це робити.
Приклади сфер, де AI може зіграти злий жарт з людьми
40:19 Приклад?
Політики, які будуть впливати на свідомість, щоб бути обраними.
Продажі неякісних товарів або товарів, які вам непотрібні. Наприклад, винайдення чогось такого, виведення його в тренди. Олівці якісь там, без чого, по суті, можна жити. Знаєте, є такий термін зараз - "споживацтво". іРhone - гарний приклад. Весь час виходить новий iPhone, і просто це ціла істерія, це черги в магазинах... Це якраз гарний приклад, коли нав'язують, що тобі треба купувать, купувать, купувать. Людині цього не треба, вона може бути щаслива без цього, так що приклади...
Пропаганда. Ти можеш взяти якусь країну, в історії вже таке було, коли якийсь африканський народ довели до того, що вони вірили в чаклунів, вони вирізали цілі зони, прибігали туди з мачете і вбивали людей, тому що їм сказали, що то чаклуни, маги якісь. І вони у це вірили.
Але технології стають дуже потужними, і якщо ми будемо застосовувати АІ, штучний інтелект, і аналізувати поведінку людей, то їм можна нав'язати будь-яку думку, і це дуже небезпечно.
41:38
Ще один дуже небезпечний тренд - це зброя. Тобто Ілон Маск і науковці збиралися у минулому році, і вони підписали меморандум, що штучний інтелект ніколи не повинен використовуватися для зброї. Але зараз він використовується, тобто зараз ці ж самі Javeline ракети, вони бачать танк, вони його розпізнають і вони в нього влучають.
Маються на увазі більш автоматизовані системи, які будуть автоматично наводитися, автоматично знищувати людей, - оце дуже небезпечно, тому що це майже неможливо контролювати. Тому що алгоритм не розпізнає, свій чи чужий.
Хто відповідальний за розвиток технологій людства, інженери або політики
42:15 І це наступний челендж. Хто бере участь, тобто як ти вважаєш, це завдання інженерів, чи все-таки політиків?
Технологія - це завжди просто набір ноликів та одиничок. Це людина перед ноутбуком, яка тренує ту мережу, або робить технічно. Це як інженер - вона реалізує бажання, закручує ту гаєчку. А хто вже вибудовує стратегію, як використовувати цей прилад, або як інтегрувати його в соціум, - це вже питання. Це вже питання до політиків, до держави і т.д.
Мені здається, що повинна бути глобальна стратегія держави на впровадження штучного інтелекту. От в Китаї у них там стратегія: вони в деяких провінціях запровадили цей personal score, по якому тобі дають знижку на квиток на поїзд, якщо ти гарно себе поводив. Але це ж питання, що вважати гарно.
video-detecting по людям - популярна іграшка, як вона може бути застосовна для бізнесу
43:07 Підходячи до цієї теми, video-detecting по людям, там дві технології: раніше було bounding boxing - ми визначали, де в зображенні там взагалі людина знаходиться. Зараз все більше object-detecting, який цікавить. Чому і де це в бізнесі застосовується?
Раніше це було просто знайти в кадрі, що десь у цій зоні цей об'єкт. Тобто не було важливо, де його зона, якщо він шукає людину, він знаходить. Якщо дві людини поруч - він їх знаходить, що це люди. Або людина, і він такий великий квадрат малює. І було неважливо... Ми знали, що в кадрі людина. Тепер важливо. Якщо, наприклад, AmazonGo - магазин, де людина бере товари з полиці, треба трекати, що це ось ця людина - точність. Коли ми бачимо, що це рука ось цієї людини, і вона взяла цей товар, в нього була interaction - взаємодія цієї людини з цим товаром. І тоді можна протрекати, що вона його взяла з полиці, поклала собі в кошик, і що це треба оплатити. Підвищення точності дає бізнесу можливість... Те, що неможливо було зробити раніше, наприклад, зробити автоматичний трекінг покупок, і т.д.
Те ж саме на площі: у тебе є багато людей, і потрібно кожного окремо порахувати, або виділити, або треба порахувати, скільки чоловіків і жінок, або підлітків і т.д., будь-яку аналітику зібрати. Для того, щоб зрозуміти, що в цьому cloud-і відбувається, неможливо це зробити старою технологією. Тому якраз сегментація, вирізання контурів людини чи обличчя...
Для чого знадобилося ідентифікували пози людини на відео для великого автомотива. Розпізнавання положень тіла може рятувати життя
44:45 А ще у виступі ти кажеш про те, що хайп поточний - це не просто визначити людину, а визначити її позу. А для чого?
Якщо, наприклад, ми робили секретний проєкт, не буду казати, для великого автомотіва. В них проблема - конвеєрна лінія. Вони збирають машини, і зупинка на хвилину конвеєрної лінії коштує цьому гіганту 1 мільйон євро. У них є факт, що за місяць вона зупиняється там н-кількість годин або разів. І вони кажуть: “Добре, ми маємо факт, чому це сталося, і людина, яка це зробила, вона йде на спеціальну процедуру, там описує, що було, для того, щоб ми розібралися, чи правильно все працює, чи щось там наплутали”. Але людина завжди боїться, що її звільнять, вона дає неправдиву інформацію... До речі, ще GDPR privacy, тобто не можна ставити камеру. Є спеціальні технології, в яких там можна використовувати радар, камеру, і навчити цей радар бачити людину як об'єкт, і потім розпізнати її позу, що вона робила. І ти можеш тоді записати 24/7, як людина збирає машину, скручує, що відбувається, і тоді будемо мати ось таку повну картинку, що трапилося, що було за годину чи дві до того, скільки він працював, може, йому там штани муляли, і йому було щось незручно. І можна тоді зрозуміти причину, чому так сталося. І для бізнесу це корисно.
Наприклад: якщо є якась поза bus driver-а, якщо він починає засинати, в нього змінюються рухи, і це не тільки про позу, а про поведінку об'єкта. Наприклад, нахили голови дуже незначні. Але якщо ми бачимо не просто голову в кадрі, вона так, як і була. А якщо вона починає отак падати, то людина засинає. Або очі заплющуються. Оці маленькі деталі вже можна відтворити, що через десять хвилин вона повністю засне, і буде аварія. І (потрібно) розбудити і зупинити машину чи що завгодно.
Інвестиційний банк задіяв штучний інтелект у визначенні інвестиційної привабливості, і чи потрібні їм тепер експерти-люди
47:03 На 20 хвилині виступу ти розповідаєш, як один інвестиційний фонд вирішив застосувати нейромережі для визначення прибуткових або неприбуткових стартапів. У мене відразу виникло питання: у тебе є якийсь патерн, який вони хочуть знайти? Ти розповідаєш про те, що вони, дивлячись на опис, можуть це зробити, тобто це треба перекласти на математику.
У мене відразу виникає питання: через те, що вони зараз не можуть задетектити всі такі стартапи, саме тому їх експертиза людська цінна.
Як тільки нейромережа всі ці стартапи задетектить, чи не вийде так, що, оскільки вони всі задетекчені, вони перестануть бути такими прибутковими, перестануть бути унікорнами в результаті?
Я думаю, що ні, тому що можемо провести аналогію з нашою компанією, з тим, чим ми зараз у Scalarr займаємося. Ми натренували модель, ми бачимо оцей рівень fraud-у. Але наші оці погані хлопці, які підробляють трафік, вони весь час міняють алгоритми. Те ж саме відбувається з цим invest-банком. Вони натренували систему, вона почала бачити, а потім щось відбулося в світі, що змінило правила оцінки. Більш вже неважливі ті правила, які були, і треба перетреновувати мережі. Тобто я б не сказав, що АІ повністю замінить людей. Тобто людина робить багато рутинної роботи. Щоб проаналізувати компанію, треба прочитати 20 сторінок а4. А штучний інтелект шукає ключову інформацію, і з 20 сторінок робить одну. І, читаючи одну сторінку, людина дізнається, чи треба інвестувати, чи ні. Тобто вона робить final decision. Може, пізніше ми дійдемо до того, що ці алгоритми стануть настільки просунутими, що ми зможемо замінити повністю людину. Але це ще не зараз.
АІ активно використовують у всьому світі в якості обчислювально-обробного мозку, а як з його втіленням в реальному тілі у вигляді роботів
49:07 І на фінал якраз. Ти коли чуєш “штучний інтелект”, “deep learning”, “машинне навчання”, то уявляєш собі, м'яко кажучи, термінатора якогось, що ми йдемо кудись до штучного інтелекту. Насправді тут відразу ми переключаємося на ідентифікацію паразитів на рибах, або груш, або апельсинів на деревах. І якось не в'яжеться. Тобто ми все-таки рухаємося туди, або це все-таки різні речі?
Я дуже радий, що ви спитали. Саме сьогодні, в день запису цього інтерв'ю, компанія Boston Dynamics запустила в масовий продаж перших роботів, оцих собачок, - я не пам'ятаю, як вони називаються, - автономних роботів, які будуть жити з людиною. Це перший приклад, коли це масс продакшн, його вже можна купити для дому. Тобто задача яка? Він може щось носити, навігуватися по квартирі, відкривати двері, і т.д. Ви розумієте, що перший раз у історії людства запустили робота в наше життя? Тобто це не робот-пилосос, який їздить, а це на ногах, як собака, який ходить.
Просто ми бачимо, розумієте, ми бачимо багато прикладів застосування: там риби, паразити, prediction компанії, детекція fraud-у, фінансові зловживання - це одна ніша. А друга - це роботікси - це дуже потужна ніша. Вже всі виробництва компаній машини збирають на роботизованих лініях. Тепер роботи будуть допомагати в нашому повсякденному житті. Є вже екзоскелети, які з'явилися і допомагають людині легше ходити, знімати навантаження і т.д. Просто про це не так широко публікують, щоб не лякати. Але робот, який стрибає, робить сальто і ходить, і може розпізнавати об'єкти, носити коробки, вже є.
Коли людина почне зливатися з технікою, вживляючи собі чіпи і перетворюючись в біомеханизм, яку міць він отримає. І що буде з незгодними
50:59 Для людства чи не вийде так, що ми станемо не самою верхівкою цивілізації і розвитку?
Я би так сказав: дивіться, що робить Ілон Маск. Він запустив компанію, Facebook викупає стартап, який керує комп'ютером за допомогою мозку, Ілон Маск заснував ще один стартап Neuralink, який поєднує комп'ютер і мозок. Тобто ми що бачимо? Що людина хоче підсилювати свій мозок за допомогою алгоритма. Чому? Тому що, коли тобі задають питання, що відбулося в 1573 році на березі якоїсь річки, твій мозок не може запам'ятати всі факти, а мережа може. Якщо в тебе є лінк до мережі, ти можеш відповідати на будь-яке питання, ти можеш аналізувати дуже багато фактів. Але як це буде відбуватися, ми дізнаємося років через 20, коли це вбудується. Тобто людина буде біонічною. Хто захоче, може вбудовувати собі чіп для авторизації - це просто зручно. Хтось може вбудовувати чіп в голову, який буде тебе просто конектити до мережі без смартфона. Це теж буде зручно. Може, через 20 років так всі будуть робити. Алгоритми будуть все більше і більше розвиватися, ставати розумними, ми будемо покращувати якість, точність і т.д.
Але будуть і люди, які будуть казати “Ні”. Вони будуть "старовіри", як то кажуть. Вони будуть їхати в ліс і казати: “Я тут живу по старим правилам”, як оце, знаєте, у футуристичних фільмах показують. Це все буде, мені здається. Просто не треба цього всього лякатися, як мобільних телефонів, веб-сайтів. Це все прийде.
Ок. Дякую, Борисе, за цікаве інтерв'ю.
Бажаєте бути в курсі новин? Дивіться наші відео на каналі Perceptron >>>
Наші контакти >>>

- Контент-маркетолог TQM systems Nataliya Raevskaya
- 6/12/2020 10:19:13 PM
-
Інтерв'ю


